 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERSONA: An Application for Emotion Recognition, Gender Recognition and Age Estimation
Paper and Code
Jun 10, 2024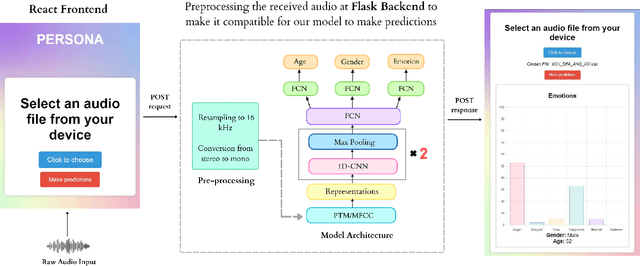
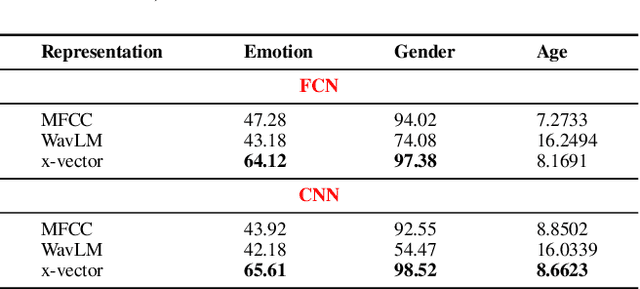
Emotion Recognition (ER), Gender Recognition (GR), and Age Estimation (AE) constitute paralinguistic tasks that rely not on the spoken content but primarily on speech characteristics such as pitch and tone. While previous research has made significant strides in developing models for each task individually, there has been comparatively less emphasis on concurrently learning these tasks, despite their inherent interconnectedness. As such in this demonstration, we present PERSONA, an application for predicting ER, GR, and AE with a single model in the backend. One notable point is we show that representations from speaker recognition pre-trained model (PTM) is better suited for such a multi-task learning format than the state-of-the-art (SOTA) self-supervised (SSL) PTM by carrying out a comparative study. Our methodology obviates the need for deploying separate models for each task and can potentially conserve resources and time during the training and deployment phases.