Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Values from Observation
Paper and Code
May 20, 2019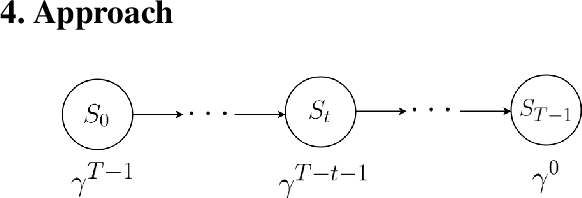
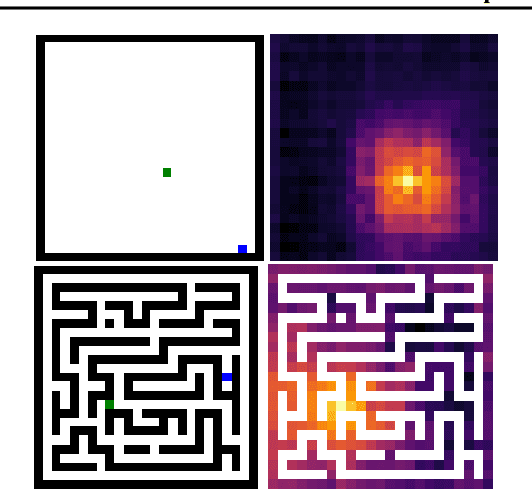
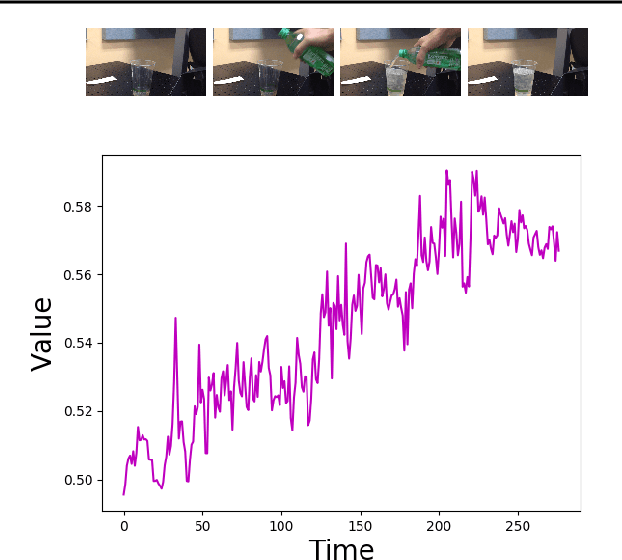
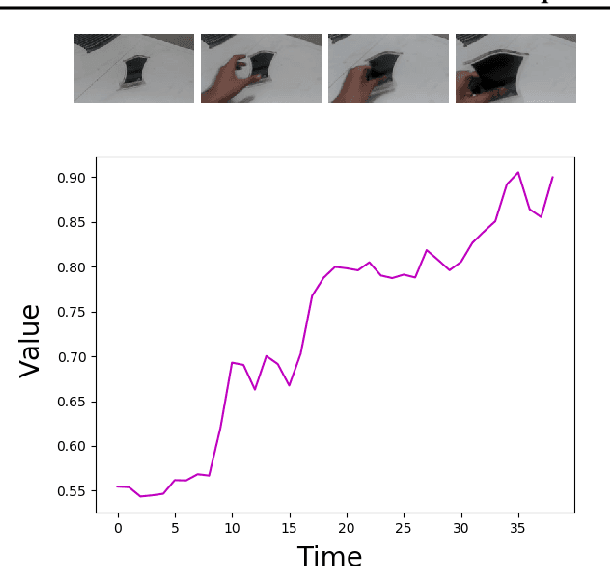
Imitation by observation is an approach for learning from expert demonstrations that lack action information, such as videos. Recent approaches to this problem can be placed into two broad categories: training dynamics models that aim to predict the actions taken between states, and learning rewards or features for computing them for Reinforcement Learning (RL). In this paper, we introduce a novel approach that learns values, rather than rewards, directly from observations. We show that by using values, we can significantly speed up RL by removing the need to bootstrap action-values, as compared to sparse-reward specifications.
* Accepted into the Workshop on Self-Supervised Learning at ICML 2019
View paper on