Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Conversational Head Generation with Regularized Driver and Enhanced Renderer
Paper and Code


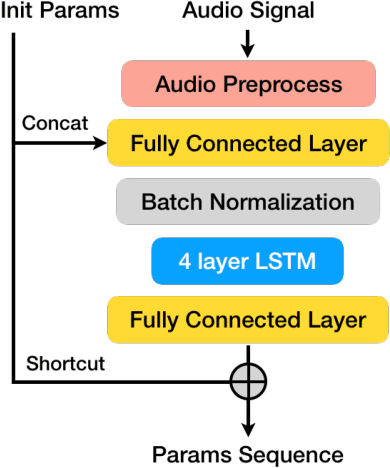

This paper reports our solution for MultiMedia ViCo 2022 Conversational Head Generation Challenge, which aims to generate vivid face-to-face conversation videos based on audio and reference images. Our solution focuses on training a generalized audio-to-head driver using regularization and assembling a high visual quality renderer. We carefully tweak the audio-to-behavior model and post-process the generated video using our foreground-background fusion module. We get first place in the listening head generation track and second place in the talking head generation track in the official ranking. Our code will be released.
* 5 pages, 4 figures, MultiMedia 2022 Workshop
View paper on