Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePE-former: Pose Estimation Transformer
Paper and Code
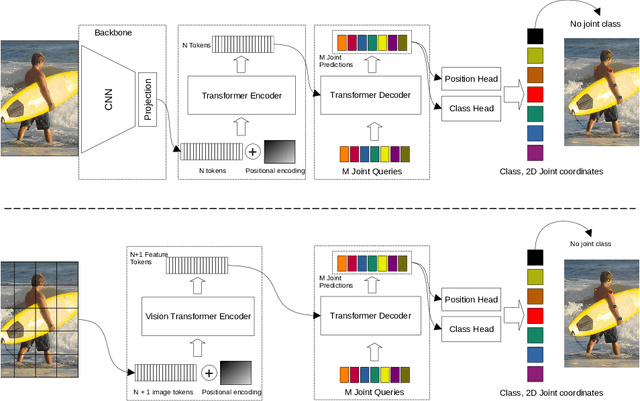
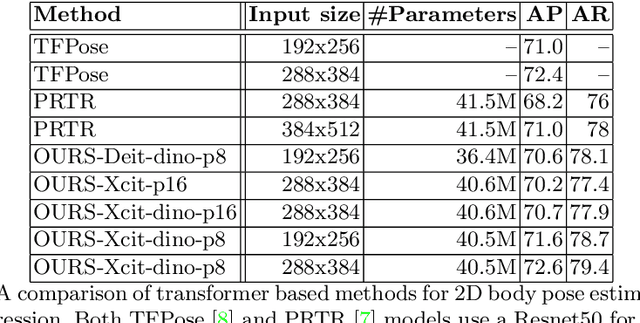
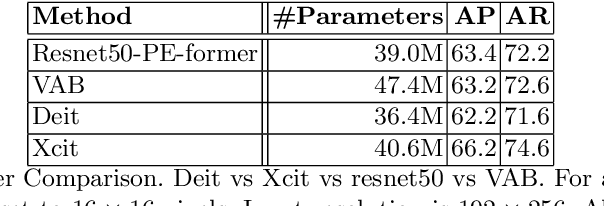
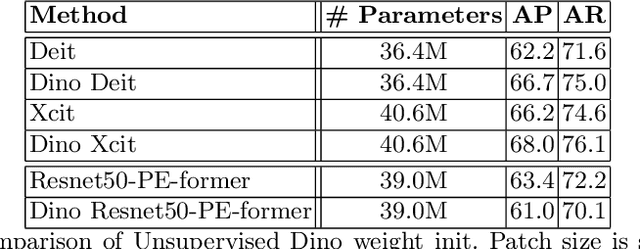
Vision transformer architectures have been demonstrated to work very effectively for image classification tasks. Efforts to solve more challenging vision tasks with transformers rely on convolutional backbones for feature extraction. In this paper we investigate the use of a pure transformer architecture (i.e., one with no CNN backbone) for the problem of 2D body pose estimation. We evaluate two ViT architectures on the COCO dataset. We demonstrate that using an encoder-decoder transformer architecture yields state of the art results on this estimation problem.
View paper on