 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDC -- a probabilistic distributional clustering algorithm: a case study on suicide articles in PubMed
Paper and Code
Dec 04, 2019
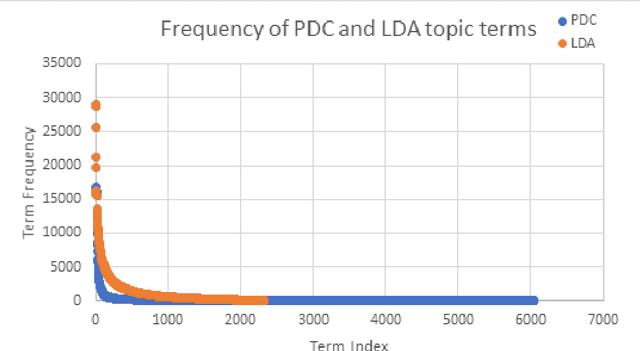
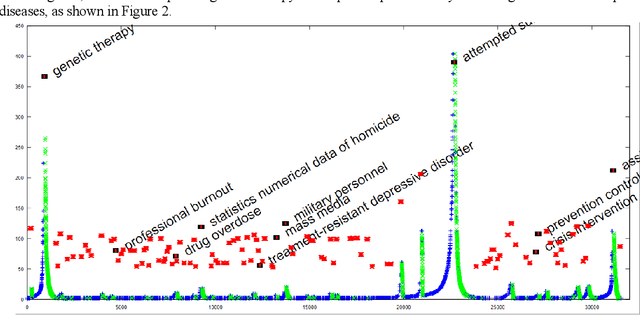

The need to organize a large collection in a manner that facilitates human comprehension is crucial given the ever-increasing volumes of information. In this work, we present PDC (probabilistic distributional clustering), a novel algorithm that, given a document collection, computes disjoint term sets representing topics in the collection. The algorithm relies on probabilities of word co-occurrences to partition the set of terms appearing in the collection of documents into disjoint groups of related terms. In this work, we also present an environment to visualize the computed topics in the term space and retrieve the most related PubMed articles for each group of terms. We illustrate the algorithm by applying it to PubMed documents on the topic of suicide. Suicide is a major public health problem identified as the tenth leading cause of death in the US. In this application, our goal is to provide a global view of the mental health literature pertaining to the subject of suicide, and through this, to help create a rich environment of multifaceted data to guide health care researchers in their endeavor to better understand the breadth, depth and scope of the problem. We demonstrate the usefulness of the proposed algorithm by providing a web portal that allows mental health researchers to peruse the suicide-related literature in PubMed.