 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathologies in information bottleneck for deterministic supervised learning
Paper and Code
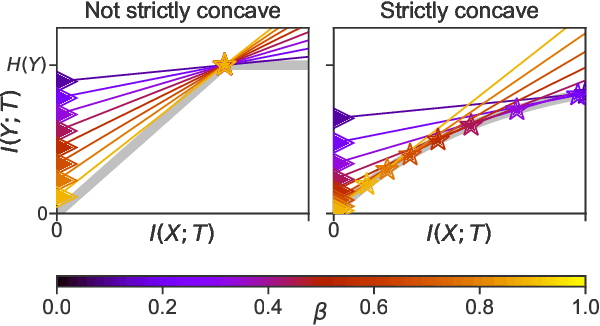
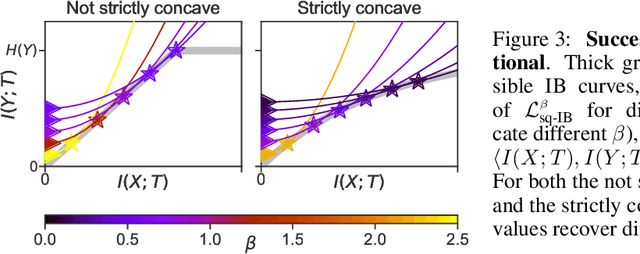
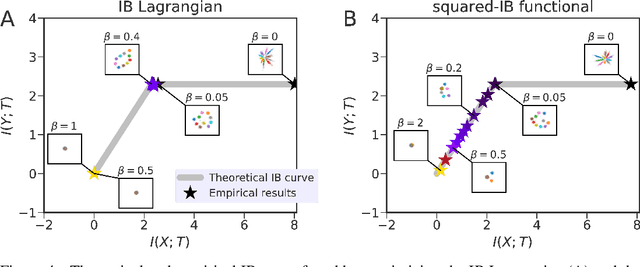
Information bottleneck (IB) is a method for extracting information from one random variable $X$ that is relevant for predicting another random variable $Y$. To do so, IB identifies an intermediate "bottleneck" variable $T$ that has low mutual information $I(X;T)$ and high mutual information $I(Y;T)$. The "IB curve" characterizes the set of bottleneck variables that achieve maximal $I(Y;T)$ for a given $I(X;T)$, and is typically explored by optimizing the "IB Lagrangian", $I(Y;T) - \beta I(X;T)$. Recently, there has been interest in applying IB to supervised learning, particularly for classification problems that use neural networks. In most classification problems, the output class $Y$ is a deterministic function of the input $X$, which we refer to as "deterministic supervised learning". We demonstrate three pathologies that arise when IB is used in any scenario where $Y$ is a deterministic function of $X$: (1) the IB curve cannot be recovered by optimizing the IB Lagrangian for different values of $\beta$; (2) there are "uninteresting" solutions at all points of the IB curve; and (3) for classifiers that achieve low error rates, the activity of different hidden layers will not exhibit a strict trade-off between compression and prediction, contrary to a recent proposal. To address problem (1), we propose a functional that, unlike the IB Lagrangian, can recover the IB curve in all cases. We finish by demonstrating these issues on the MNIST dataset.