 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle Filter Bridge Interpolation
Paper and Code
Mar 27, 2021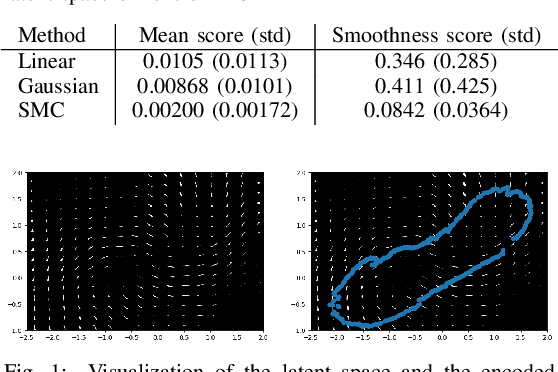



Auto encoding models have been extensively studied in recent years. They provide an efficient framework for sample generation, as well as for analysing feature learning. Furthermore, they are efficient in performing interpolations between data-points in semantically meaningful ways. In this paper, we build further on a previously introduced method for generating canonical, dimension independent, stochastic interpolations. Here, the distribution of interpolation paths is represented as the distribution of a bridge process constructed from an artificial random data generating process in the latent space, having the prior distribution as its invariant distribution. As a result the stochastic interpolation paths tend to reside in regions of the latent space where the prior has high mass. This is a desirable feature since, generally, such areas produce semantically meaningful samples. In this paper, we extend the bridge process method by introducing a discriminator network that accurately identifies areas of high latent representation density. The discriminator network is incorporated as a change of measure of the underlying bridge process and sampling of interpolation paths is implemented using sequential Monte Carlo. The resulting sampling procedure allows for greater variability in interpolation paths and stronger drift towards areas of high data density.