 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Order Pruning: for Best Speed/Accuracy Trade-off in Neural Architecture Search
Paper and Code

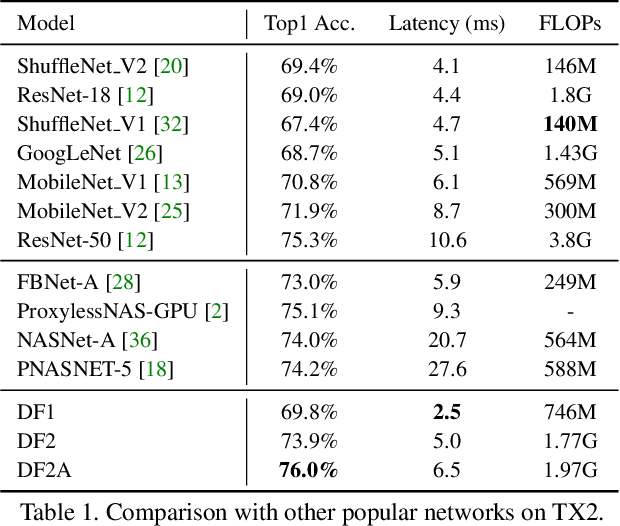

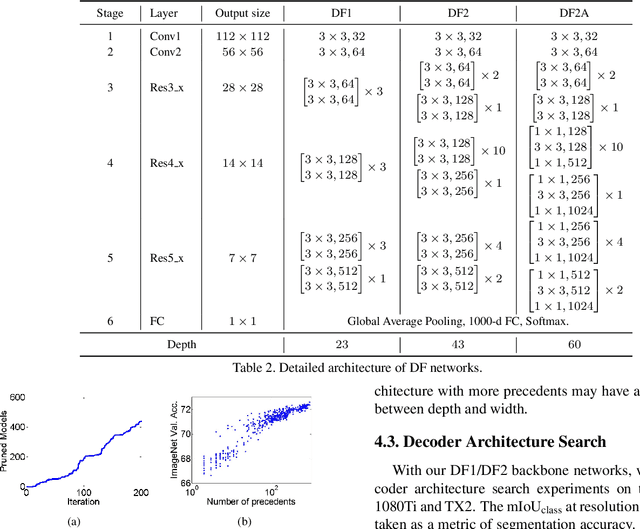
Achieving good speed and accuracy trade-off on a target platform is very important in deploying deep neural networks in real world scenarios. However, most existing automatic architecture search approaches only concentrate on high performance. In this work, we propose an algorithm that can offer better speed/accuracy trade-off of searched networks, which is termed "Partial Order Pruning". It prunes the architecture search space with a partial order assumption to automatically search for the architectures with the best speed and accuracy trade-off. Our algorithm explicitly takes profile information about the inference speed on the target platform into consideration. With the proposed algorithm, we present several Dongfeng (DF) networks that provide high accuracy and fast inference speed on various application GPU platforms. By further searching decoder architectures, our DF-Seg real-time segmentation networks yield state-of-the-art speed/accuracy trade-off on both the target embedded device and the high-end GPU.