Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParkPredict+: Multimodal Intent and Motion Prediction for Vehicles in Parking Lots with CNN and Transformer
Paper and Code
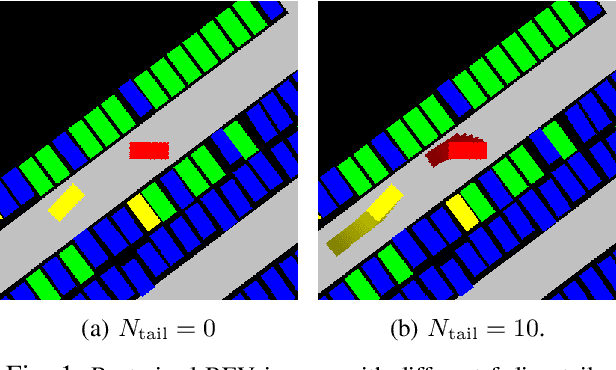


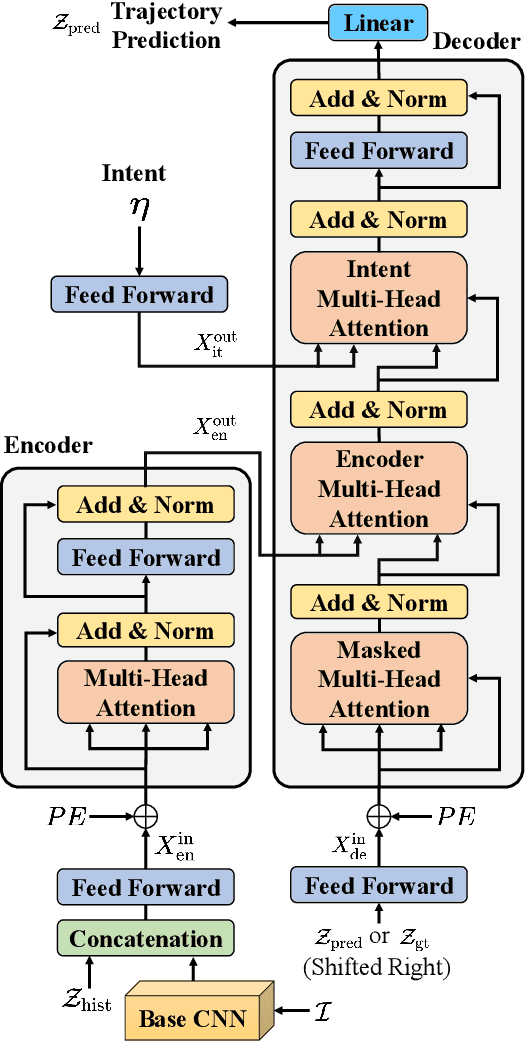
The problem of multimodal intent and trajectory prediction for human-driven vehicles in parking lots is addressed in this paper. Using models designed with CNN and Transformer networks, we extract temporal-spatial and contextual information from trajectory history and local bird's eye view (BEV) semantic images, and generate predictions about intent distribution and future trajectory sequences. Our methods outperforms existing models in accuracy, while allowing an arbitrary number of modes, encoding complex multi-agent scenarios, and adapting to different parking maps. In addition, we present the first public human driving dataset in parking lot with high resolution and rich traffic scenarios for relevant research in this field.
View paper on