 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametrized Stochastic Multi-armed Bandits with Binary Rewards
Paper and Code
Nov 18, 2011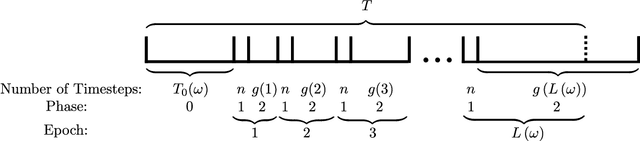
In this paper, we consider the problem of multi-armed bandits with a large, possibly infinite number of correlated arms. We assume that the arms have Bernoulli distributed rewards, independent across time, where the probabilities of success are parametrized by known attribute vectors for each arm, as well as an unknown preference vector, each of dimension $n$. For this model, we seek an algorithm with a total regret that is sub-linear in time and independent of the number of arms. We present such an algorithm, which we call the Two-Phase Algorithm, and analyze its performance. We show upper bounds on the total regret which applies uniformly in time, for both the finite and infinite arm cases. The asymptotics of the finite arm bound show that for any $f \in \omega(\log(T))$, the total regret can be made to be $O(n \cdot f(T))$. In the infinite arm case, the total regret is $O(\sqrt{n^3 T})$.