 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Restarted SGD for Non-Convex Optimization with Faster Convergence and Less Communication
Paper and Code
Jul 17, 2018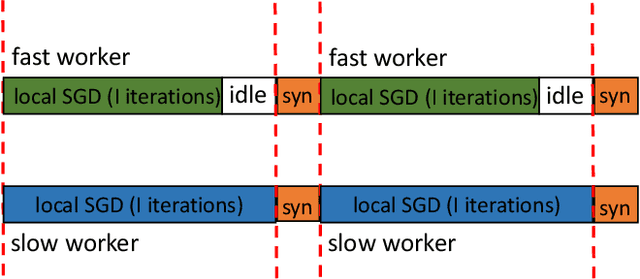

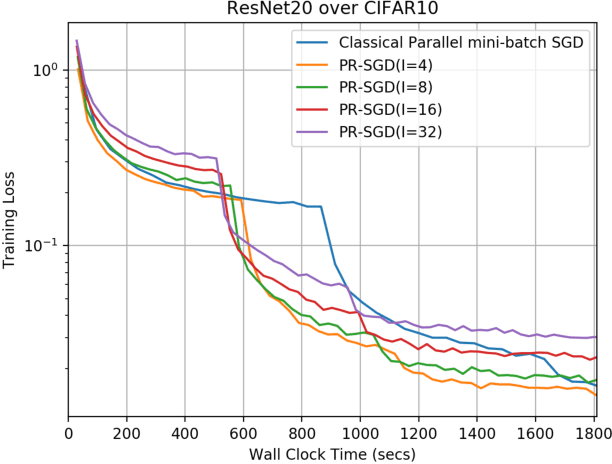
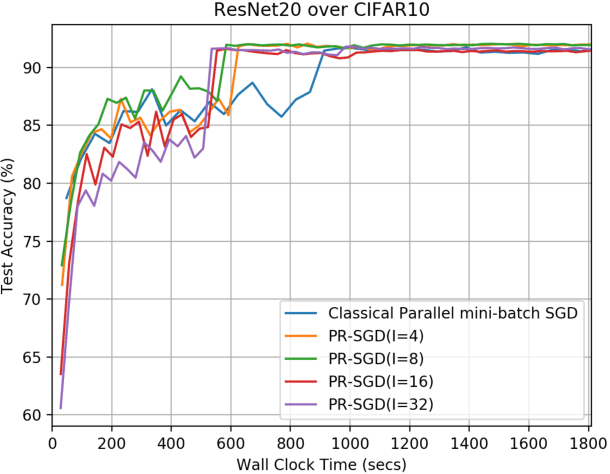
For large scale non-convex stochastic optimization, parallel mini-batch SGD using multiple workers ideally can achieve a linear speed-up with respect to the number of workers compared with SGD over a single worker. However, such linear scalability in practice is significantly limited by the growing demand for communication as more workers are involved. This is because the classical parallel mini-batch SGD requires gradient or model exchanges between workers (possibly through an intermediate server) at every iteration. In this paper, we study whether it is possible to maintain the linear speed-up property of parallel mini-batch SGD by using less frequent message passing between workers. We consider the parallel restarted SGD method where each worker periodically restarts its SGD by using the node average as a new initial point. Such a strategy invokes inter-node communication only when computing the node average to restart local SGD but otherwise is fully parallel with no communication overhead. We prove that the parallel restarted SGD method can maintain the same convergence rate as the classical parallel mini-batch SGD while reducing the communication overhead by a factor of $O(T^{1/4})$. The parallel restarted SGD strategy was previously used as a common practice, known as model averaging, for training deep neural networks. Earlier empirical works have observed that model averaging can achieve an almost linear speed-up if the averaging interval is carefully controlled. The results in this paper can serve as theoretical justifications for these empirical results on model averaging and provide practical guidelines for applying model averaging.