 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Algorithms for Densest Subgraph Discovery Using Shared Memory Model
Paper and Code
Feb 27, 2021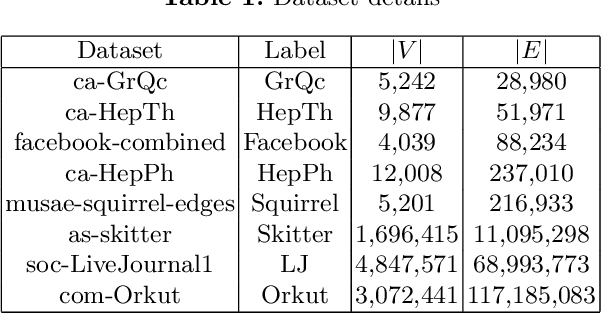
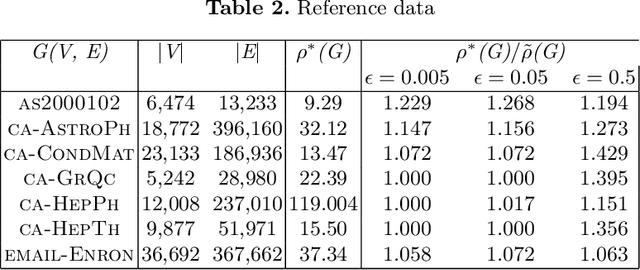
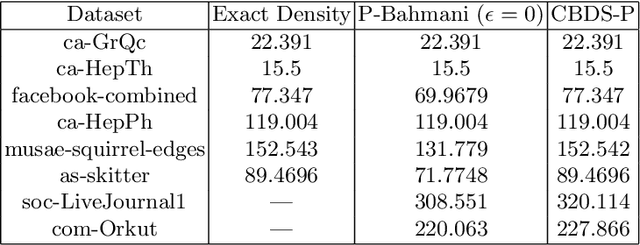
The problem of finding dense components of a graph is a widely explored area in data analysis, with diverse applications in fields and branches of study including community mining, spam detection, computer security and bioinformatics. This research project explores previously available algorithms in order to study them and identify potential modifications that could result in an improved version with considerable performance and efficiency leap. Furthermore, efforts were also steered towards devising a novel algorithm for the problem of densest subgraph discovery. This paper presents an improved implementation of a widely used densest subgraph discovery algorithm and a novel parallel algorithm which produces better results than a 2-approximation.