 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanorAMS: Automatic Annotation for Detecting Objects in Urban Context
Paper and Code
Aug 31, 2022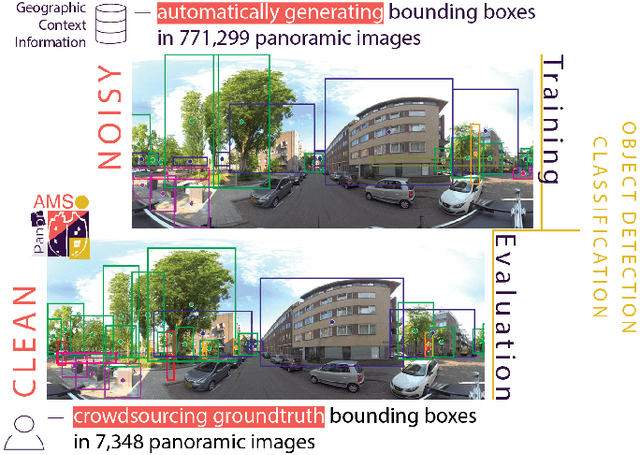

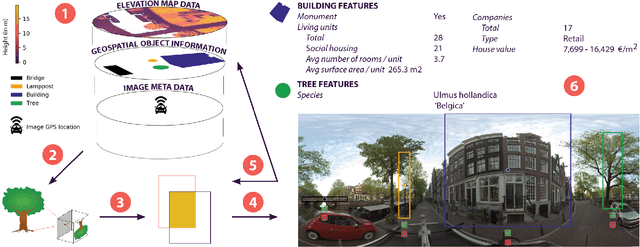
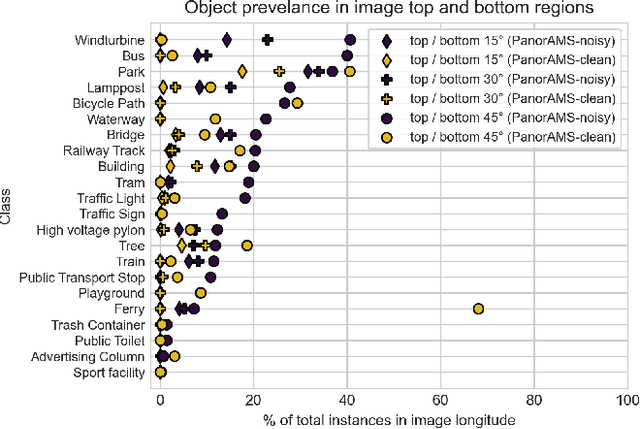
Large collections of geo-referenced panoramic images are freely available for cities across the globe, as well as detailed maps with location and meta-data on a great variety of urban objects. They provide a potentially rich source of information on urban objects, but manual annotation for object detection is costly, laborious and difficult. Can we utilize such multimedia sources to automatically annotate street level images as an inexpensive alternative to manual labeling? With the PanorAMS framework we introduce a method to automatically generate bounding box annotations for panoramic images based on urban context information. Following this method, we acquire large-scale, albeit noisy, annotations for an urban dataset solely from open data sources in a fast and automatic manner. The dataset covers the City of Amsterdam and includes over 14 million noisy bounding box annotations of 22 object categories present in 771,299 panoramic images. For many objects further fine-grained information is available, obtained from geospatial meta-data, such as building value, function and average surface area. Such information would have been difficult, if not impossible, to acquire via manual labeling based on the image alone. For detailed evaluation, we introduce an efficient crowdsourcing protocol for bounding box annotations in panoramic images, which we deploy to acquire 147,075 ground-truth object annotations for a subset of 7,348 images, the PanorAMS-clean dataset. For our PanorAMS-noisy dataset, we provide an extensive analysis of the noise and how different types of noise affect image classification and object detection performance. We make both datasets, PanorAMS-noisy and PanorAMS-clean, benchmarks and tools presented in this paper openly available.