 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANDA: Predicting the change in proteins binding affinity upon mutations using sequence information
Paper and Code
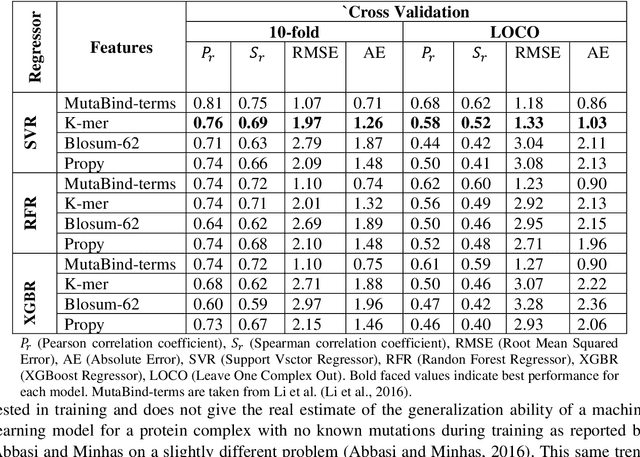

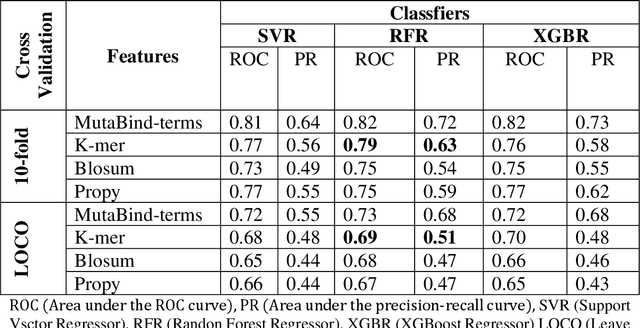
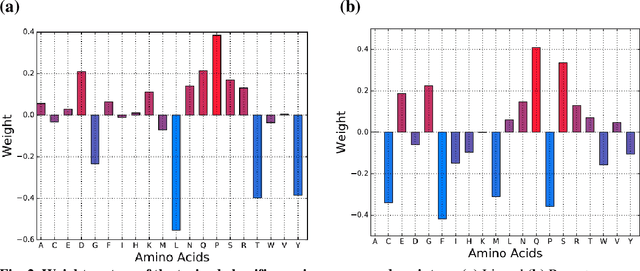
Accurately determining a change in protein binding affinity upon mutations is important for the discovery and design of novel therapeutics and to assist mutagenesis studies. Determination of change in binding affinity upon mutations requires sophisticated, expensive, and time-consuming wet-lab experiments that can be aided with computational methods. Most of the computational prediction techniques require protein structures that limit their applicability to protein complexes with known structures. In this work, we explore the sequence-based prediction of change in protein binding affinity upon mutation. We have used protein sequence information instead of protein structures along with machine learning techniques to accurately predict the change in protein binding affinity upon mutation. Our proposed sequence-based novel change in protein binding affinity predictor called PANDA gives better accuracy than existing methods over the same validation set as well as on an external independent test dataset. On an external test dataset, our proposed method gives a maximum Pearson correlation coefficient of 0.52 in comparison to the state-of-the-art existing protein structure-based method called MutaBind which gives a maximum Pearson correlation coefficient of 0.59. Our proposed protein sequence-based method, to predict a change in binding affinity upon mutations, has wide applicability and comparable performance in comparison to existing protein structure-based methods. A cloud-based webserver implementation of PANDA and its python code is available at https://sites.google.com/view/wajidarshad/software and https://github.com/wajidarshad/panda.