 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaloBoost: An Overfitting-robust TreeBoost with Out-of-Bag Sample Regularization Techniques
Paper and Code
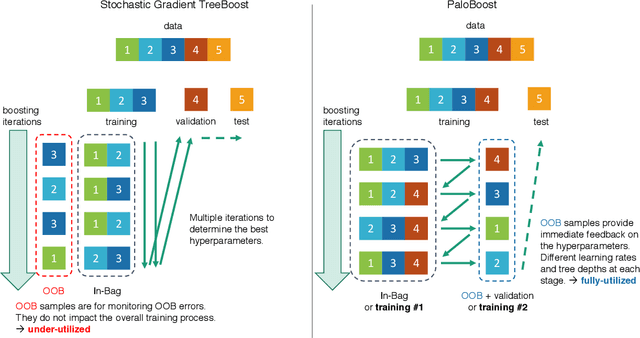
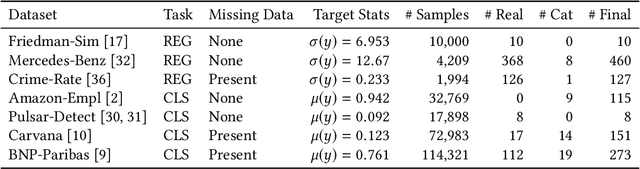
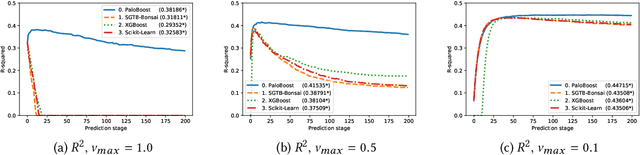
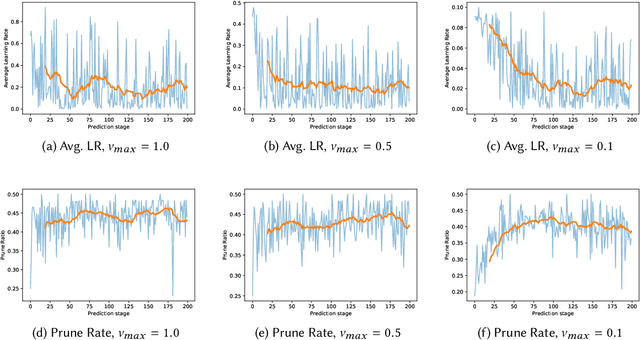
Stochastic Gradient TreeBoost is often found in many winning solutions in public data science challenges. Unfortunately, the best performance requires extensive parameter tuning and can be prone to overfitting. We propose PaloBoost, a Stochastic Gradient TreeBoost model that uses novel regularization techniques to guard against overfitting and is robust to parameter settings. PaloBoost uses the under-utilized out-of-bag samples to perform gradient-aware pruning and estimate adaptive learning rates. Unlike other Stochastic Gradient TreeBoost models that use the out-of-bag samples to estimate test errors, PaloBoost treats the samples as a second batch of training samples to prune the trees and adjust the learning rates. As a result, PaloBoost can dynamically adjust tree depths and learning rates to achieve faster learning at the start and slower learning as the algorithm converges. We illustrate how these regularization techniques can be efficiently implemented and propose a new formula for calculating feature importance to reflect the node coverages and learning rates. Extensive experimental results on seven datasets demonstrate that PaloBoost is robust to overfitting, is less sensitivity to the parameters, and can also effectively identify meaningful features.