 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalm: Predicting Actions through Language Models @ Ego4D Long-Term Action Anticipation Challenge 2023
Paper and Code
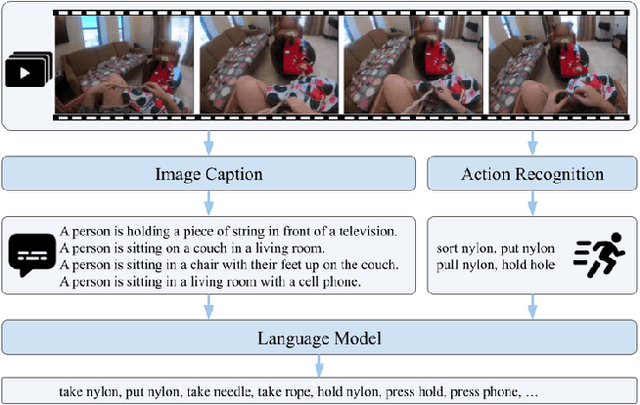
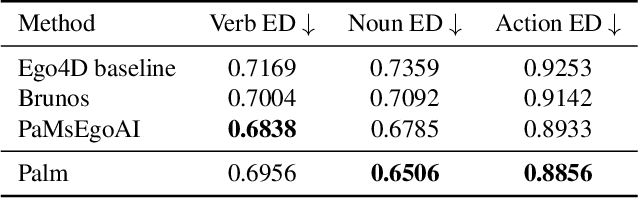

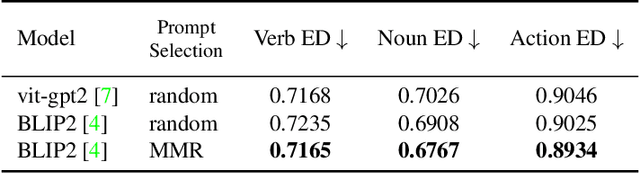
We present Palm, a solution to the Long-Term Action Anticipation (LTA) task utilizing vision-language and large language models. Given an input video with annotated action periods, the LTA task aims to predict possible future actions. We hypothesize that an optimal solution should capture the interdependency between past and future actions, and be able to infer future actions based on the structure and dependency encoded in the past actions. Large language models have demonstrated remarkable commonsense-based reasoning ability. Inspired by that, Palm chains an image captioning model and a large language model. It predicts future actions based on frame descriptions and action labels extracted from the input videos. Our method outperforms other participants in the EGO4D LTA challenge and achieves the best performance in terms of action prediction. Our code is available at https://github.com/DanDoge/Palm