 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAD-FT: A Lightweight Defense for Backdoor Attacks via Data Purification and Fine-Tuning
Paper and Code
Sep 18, 2024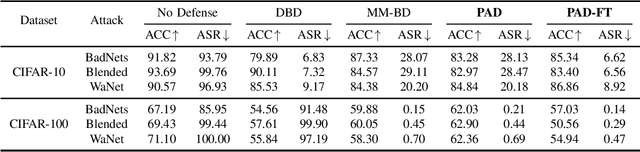
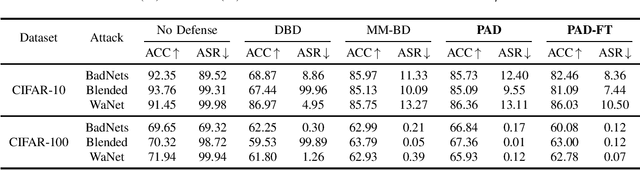

Backdoor attacks pose a significant threat to deep neural networks, particularly as recent advancements have led to increasingly subtle implantation, making the defense more challenging. Existing defense mechanisms typically rely on an additional clean dataset as a standard reference and involve retraining an auxiliary model or fine-tuning the entire victim model. However, these approaches are often computationally expensive and not always feasible in practical applications. In this paper, we propose a novel and lightweight defense mechanism, termed PAD-FT, that does not require an additional clean dataset and fine-tunes only a very small part of the model to disinfect the victim model. To achieve this, our approach first introduces a simple data purification process to identify and select the most-likely clean data from the poisoned training dataset. The self-purified clean dataset is then used for activation clipping and fine-tuning only the last classification layer of the victim model. By integrating data purification, activation clipping, and classifier fine-tuning, our mechanism PAD-FT demonstrates superior effectiveness across multiple backdoor attack methods and datasets, as confirmed through extensive experimental evaluation.