 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-DIFF: Learning Classifier with Noisy Labels based on Probability Difference Distributions
Paper and Code
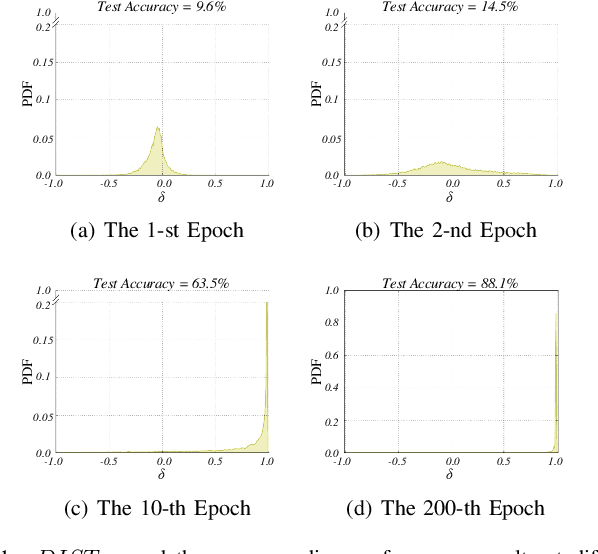
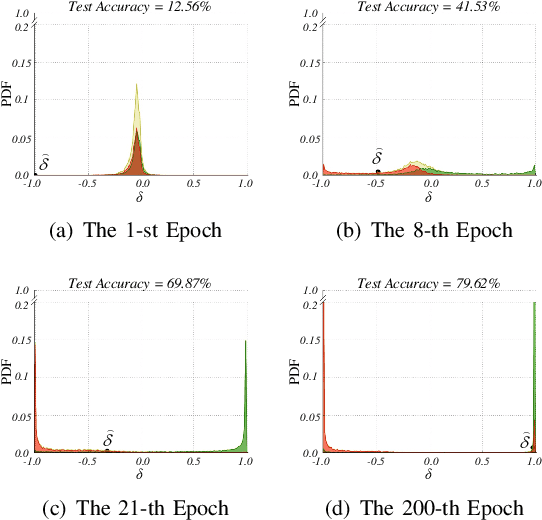
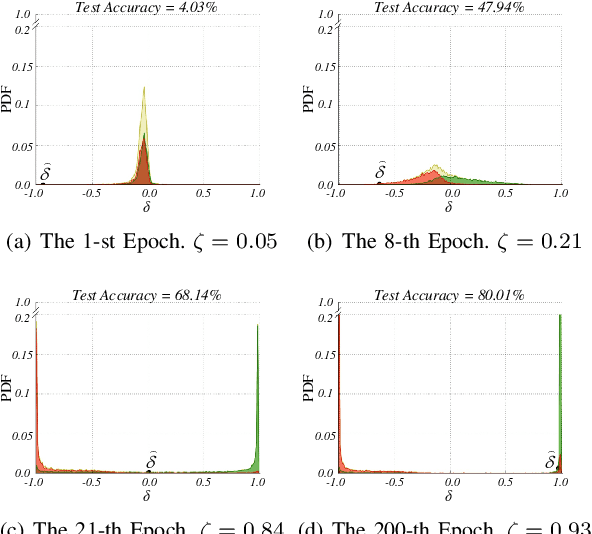
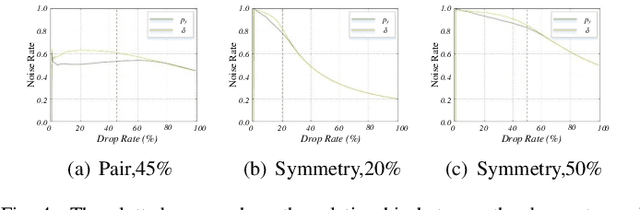
Learning deep neural network (DNN) classifier with noisy labels is a challenging task because the DNN can easily over-fit on these noisy labels due to its high capability. In this paper, we present a very simple but effective training paradigm called P-DIFF, which can train DNN classifiers but obviously alleviate the adverse impact of noisy labels. Our proposed probability difference distribution implicitly reflects the probability of a training sample to be clean, then this probability is employed to re-weight the corresponding sample during the training process. P-DIFF can also achieve good performance even without prior knowledge on the noise rate of training samples. Experiments on benchmark datasets also demonstrate that P-DIFF is superior to the state-of-the-art sample selection methods.