 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverfitting and Optimization in Offline Policy Learning
Paper and Code


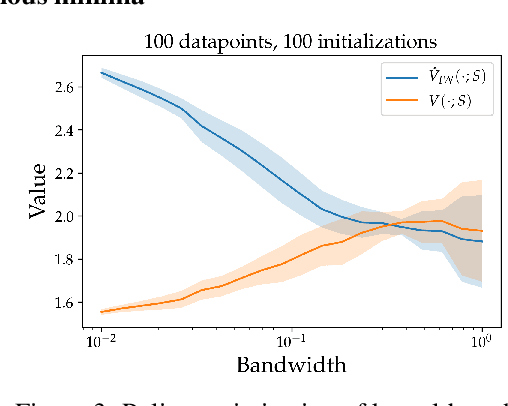

We consider the task of policy learning from an offline dataset generated by some behavior policy. We analyze the two most prominent families of algorithms for this task: policy optimization and Q-learning. We demonstrate that policy optimization suffers from two problems, overfitting and spurious minima, that do not appear in Q-learning or full-feedback problems (i.e. cost-sensitive classification). Specifically, we describe the phenomenon of ``bandit overfitting'' in which an algorithm overfits based on the actions observed in the dataset, and show that it affects policy optimization but not Q-learning. Moreover, we show that the policy optimization objective suffers from spurious minima even with linear policies, whereas the Q-learning objective is convex for linear models. We empirically verify the existence of both problems in realistic datasets with neural network models.