 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the limitations of patch-based learning to detect cancer in whole slide images
Paper and Code
Dec 01, 2020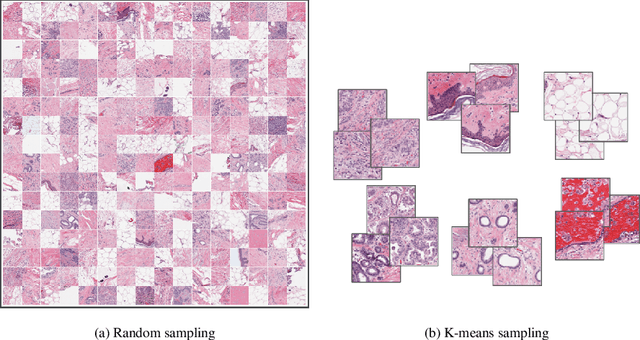
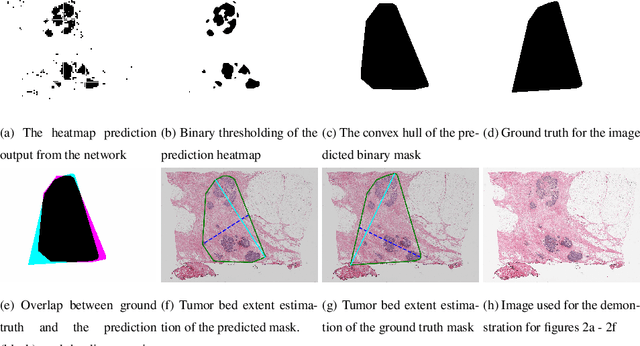
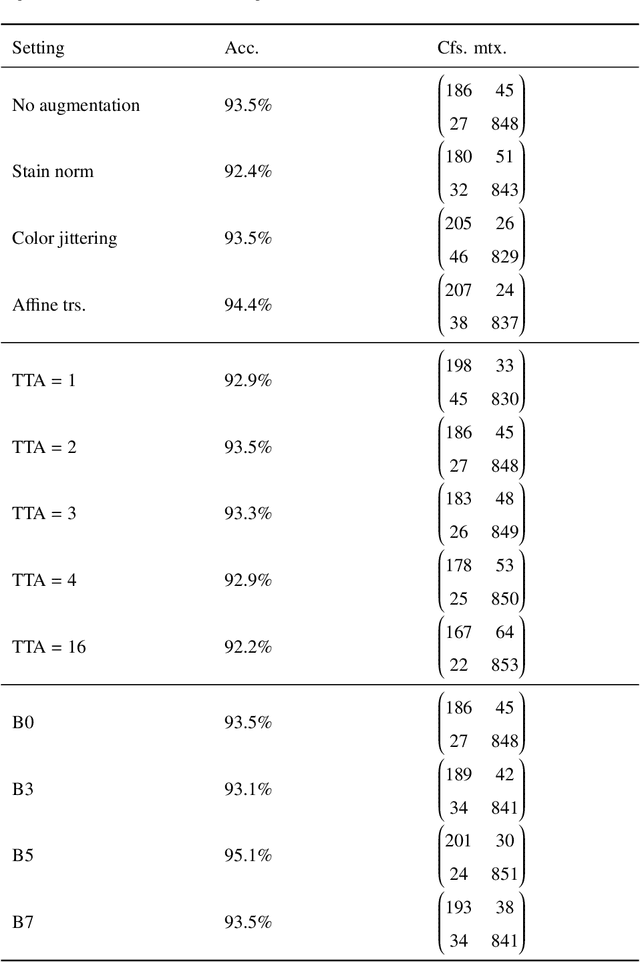
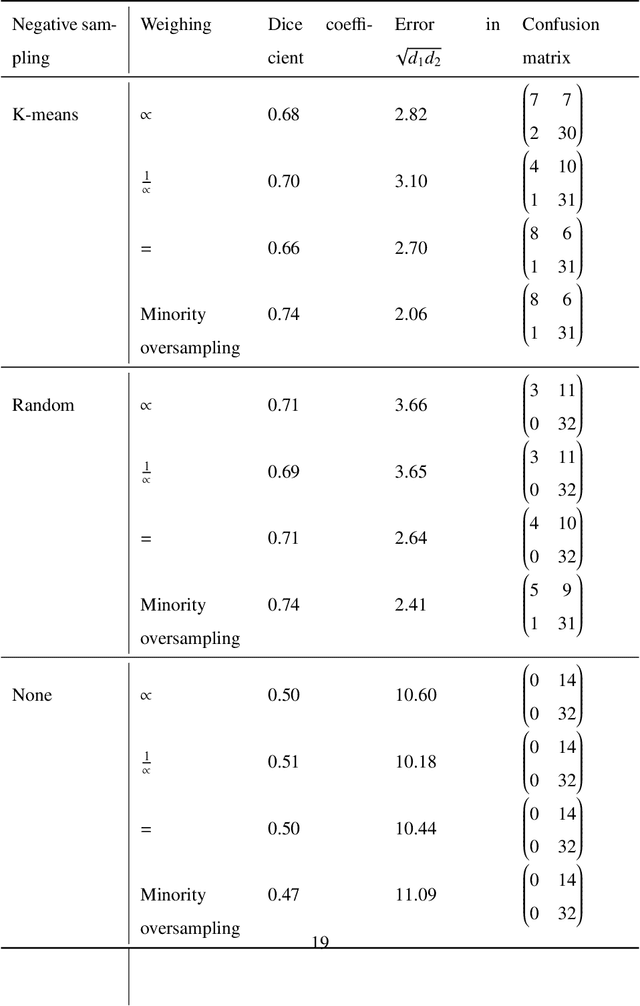
Whole slide images (WSIs) pose unique challenges when training deep learning models. They are very large which makes it necessary to break each image down into smaller patches for analysis, image features have to be extracted at multiple scales in order to capture both detail and context, and extreme class imbalances may exist. Significant progress has been made in the analysis of these images, thanks largely due to the availability of public annotated datasets. We postulate, however, that even if a method scores well on a challenge task, this success may not translate to good performance in a more clinically relevant workflow. Many datasets consist of image patches which may suffer from data curation bias; other datasets are only labelled at the whole slide level and the lack of annotations across an image may mask erroneous local predictions so long as the final decision is correct. In this paper, we outline the differences between patch or slide-level classification versus methods that need to localize or segment cancer accurately across the whole slide, and we experimentally verify that best practices differ in both cases. We apply a binary cancer detection network on post neoadjuvant therapy breast cancer WSIs to find the tumor bed outlining the extent of cancer, a task which requires sensitivity and precision across the whole slide. We extensively study multiple design choices and their effects on the outcome, including architectures and augmentations. Furthermore, we propose a negative data sampling strategy, which drastically reduces the false positive rate (7% on slide level) and improves each metric pertinent to our problem, with a 15% reduction in the error of tumor extent.