Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOur Evaluation Metric Needs an Update to Encourage Generalization
Paper and Code
Jul 14, 2020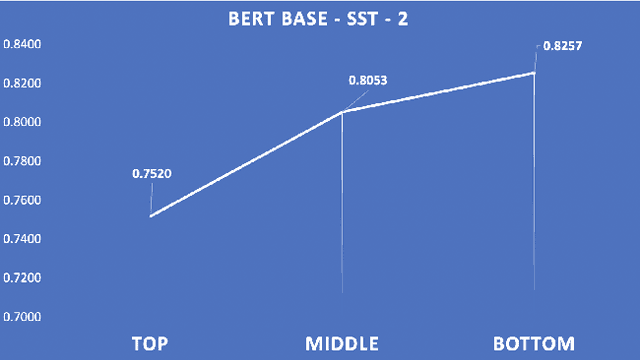
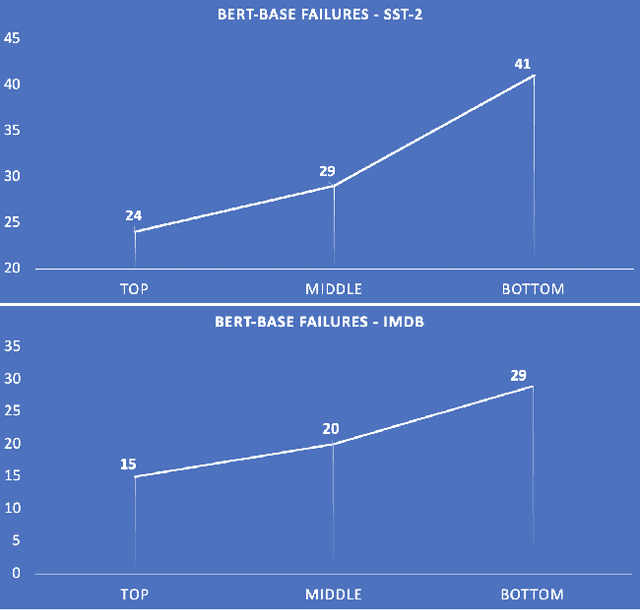
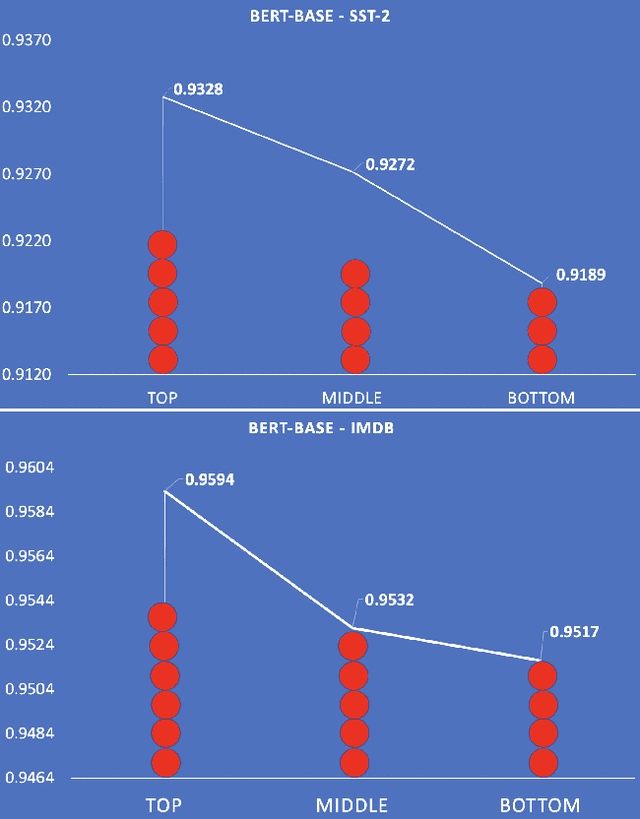
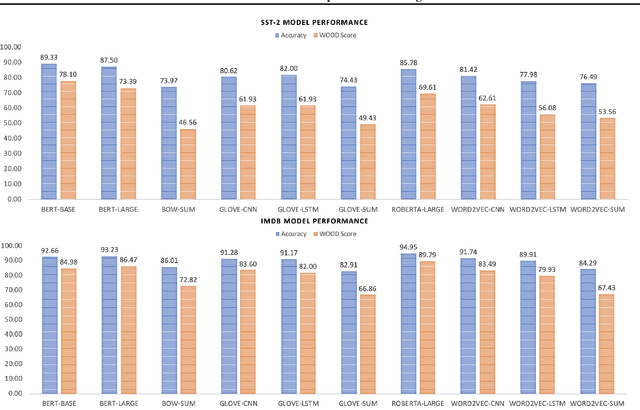
Models that surpass human performance on several popular benchmarks display significant degradation in performance on exposure to Out of Distribution (OOD) data. Recent research has shown that models overfit to spurious biases and `hack' datasets, in lieu of learning generalizable features like humans. In order to stop the inflation in model performance -- and thus overestimation in AI systems' capabilities -- we propose a simple and novel evaluation metric, WOOD Score, that encourages generalization during evaluation.
* Accepted to ICML UDL 2020
View paper on