 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrigins of Low-dimensional Adversarial Perturbations
Paper and Code
Mar 25, 2022
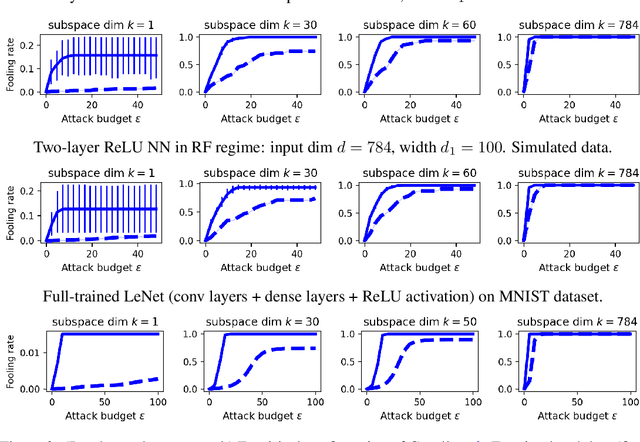


In this note, we initiate a rigorous study of the phenomenon of low-dimensional adversarial perturbations in classification. These are adversarial perturbations wherein, unlike the classical setting, the attacker's search is limited to a low-dimensional subspace of the feature space. The goal is to fool the classifier into flipping its decision on a nonzero fraction of inputs from a designated class, upon the addition of perturbations from a subspace chosen by the attacker and fixed once and for all. It is desirable that the dimension $k$ of the subspace be much smaller than the dimension $d$ of the feature space, while the norm of the perturbations should be negligible compared to the norm of a typical data point. In this work, we consider binary classification models under very general regularity conditions, which are verified by certain feedforward neural networks (e.g., with sufficiently smooth, or else ReLU activation function), and compute analytical lower-bounds for the fooling rate of any subspace. These bounds explicitly highlight the dependence that the fooling rate has on the margin of the model (i.e., the ratio of the output to its $L_2$-norm of its gradient at a test point), and on the alignment of the given subspace with the gradients of the model w.r.t. inputs. Our results provide a theoretical explanation for the recent success of heuristic methods for efficiently generating low-dimensional adversarial perturbations. Moreover, our theoretical results are confirmed by experiments.