 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORAN-Bench-13K: An Open Source Benchmark for Assessing LLMs in Open Radio Access Networks
Paper and Code
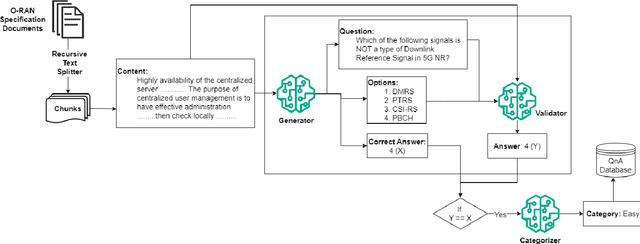
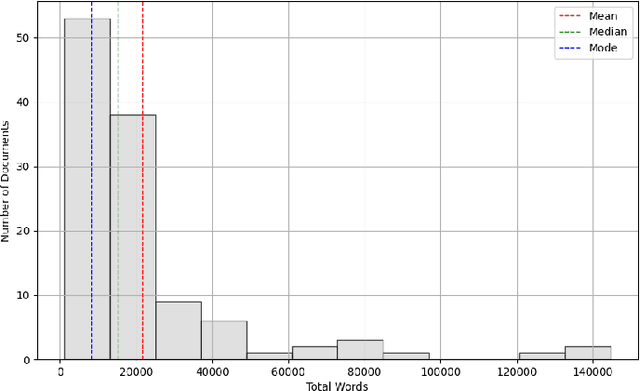
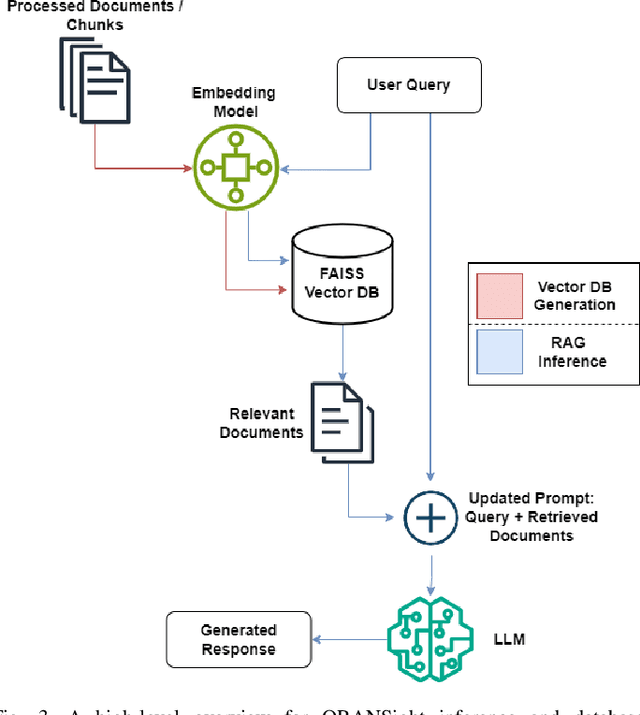
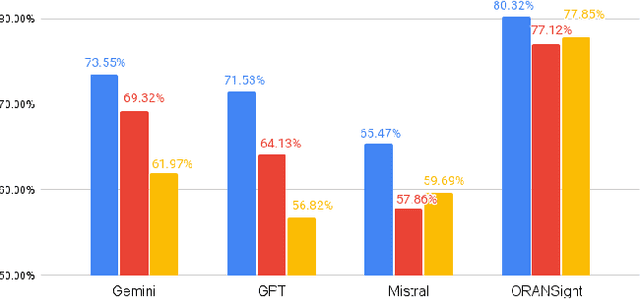
Large Language Models (LLMs) can revolutionize how we deploy and operate Open Radio Access Networks (O-RAN) by enhancing network analytics, anomaly detection, and code generation and significantly increasing the efficiency and reliability of a plethora of O-RAN tasks. In this paper, we present ORAN-Bench-13K, the first comprehensive benchmark designed to evaluate the performance of Large Language Models (LLMs) within the context of O-RAN. Our benchmark consists of 13,952 meticulously curated multiple-choice questions generated from 116 O-RAN specification documents. We leverage a novel three-stage LLM framework, and the questions are categorized into three distinct difficulties to cover a wide spectrum of ORAN-related knowledge. We thoroughly evaluate the performance of several state-of-the-art LLMs, including Gemini, Chat-GPT, and Mistral. Additionally, we propose ORANSight, a Retrieval-Augmented Generation (RAG)-based pipeline that demonstrates superior performance on ORAN-Bench-13K compared to other tested closed-source models. Our findings indicate that current popular LLM models are not proficient in O-RAN, highlighting the need for specialized models. We observed a noticeable performance improvement when incorporating the RAG-based ORANSight pipeline, with a Macro Accuracy of 0.784 and a Weighted Accuracy of 0.776, which was on average 21.55% and 22.59% better than the other tested LLMs.