Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization with access to auxiliary information
Paper and Code
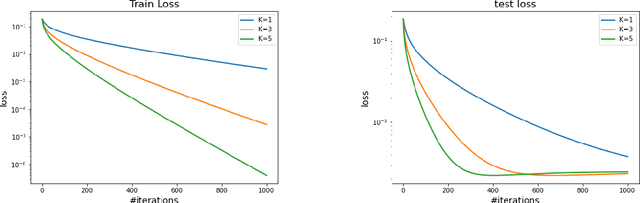
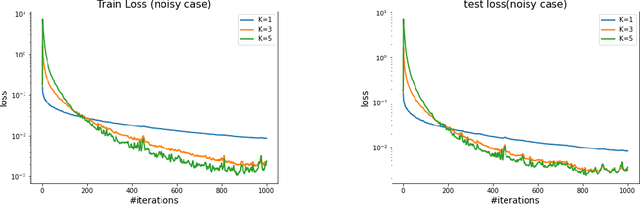

We investigate the fundamental optimization question of minimizing a target function $f(x)$ whose gradients are expensive to compute or have limited availability, given access to some auxiliary side function $h(x)$ whose gradients are cheap or more available. This formulation captures many settings of practical relevance such as i) re-using batches in SGD, ii) transfer learning, iii) federated learning, iv) training with compressed models/dropout, etc. We propose two generic new algorithms which are applicable in all these settings and prove using only an assumption on the Hessian similarity between the target and side information that we can benefit from this framework.
View paper on