 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization and Generalization Analysis of Transduction through Gradient Boosting and Application to Multi-scale Graph Neural Networks
Paper and Code
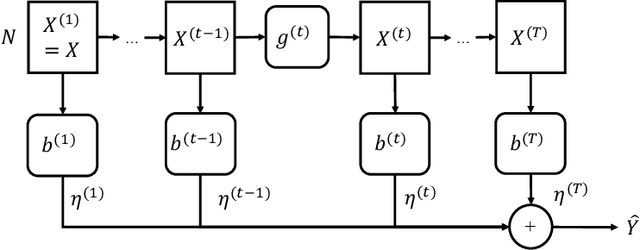



It is known that the current graph neural networks (GNNs) are difficult to make themselves deep due to the problem known as \textit{over-smoothing}. Multi-scale GNNs are a promising approach for mitigating the over-smoothing problem. However, there is little explanation of why it works empirically from the viewpoint of learning theory. In this study, we derive the optimization and generalization guarantees of transductive learning algorithms that include multi-scale GNNs. Using the boosting theory, we prove the convergence of the training error under weak learning-type conditions. By combining it with generalization gap bounds in terms of transductive Rademacher complexity, we show that a test error bound of a specific type of multi-scale GNNs that decreases corresponding to the depth under the conditions. Our results offer theoretical explanations for the effectiveness of the multi-scale structure against the over-smoothing problem. We apply boosting algorithms to the training of multi-scale GNNs for real-world node prediction tasks. We confirm that its performance is comparable to existing GNNs, and the practical behaviors are consistent with theoretical observations. Code is available at https://github.com/delta2323/GB-GNN