 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Distributionally Robust Policy Optimization
Paper and Code

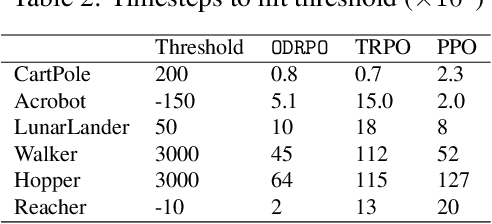
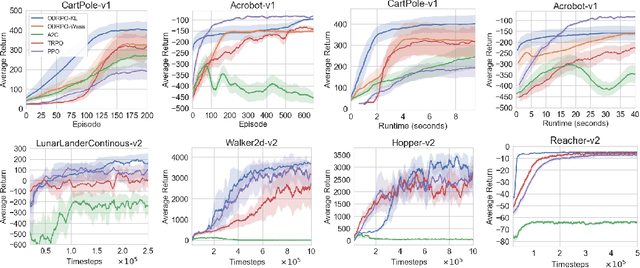

Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), as the widely employed policy based reinforcement learning (RL) methods, are prone to converge to a sub-optimal solution as they limit the policy representation to a particular parametric distribution class. To address this issue, we develop an innovative Optimistic Distributionally Robust Policy Optimization (ODRPO) algorithm, which effectively utilizes Optimistic Distributionally Robust Optimization (DRO) approach to solve the trust region constrained optimization problem without parameterizing the policies. Our algorithm improves TRPO and PPO with a higher sample efficiency and a better performance of the final policy while attaining the learning stability. Moreover, it achieves a globally optimal policy update that is not promised in the prevailing policy based RL algorithms. Experiments across tabular domains and robotic locomotion tasks demonstrate the effectiveness of our approach.