 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal No-Regret Learning in General Games: Bounded Regret with Unbounded Step-Sizes via Clairvoyant MWU
Paper and Code
Dec 19, 2021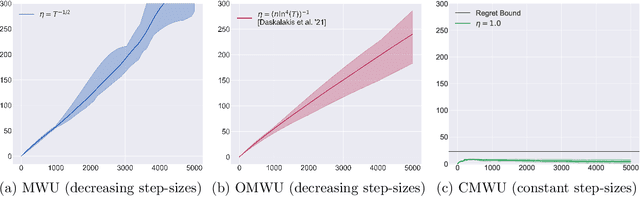
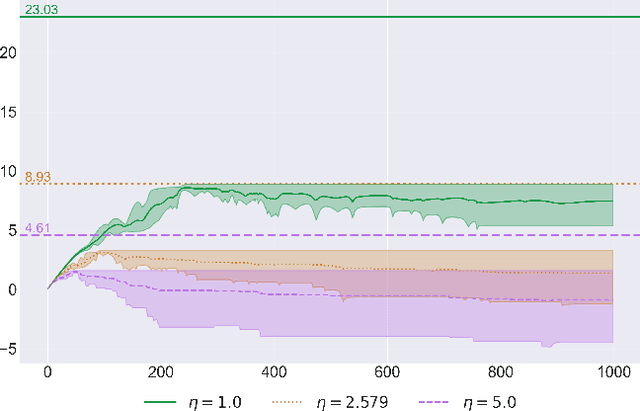
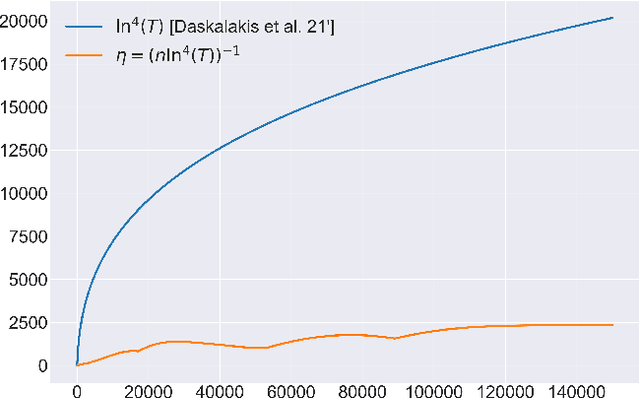
In this paper we solve the problem of no-regret learning in general games. Specifically, we provide a simple and practical algorithm that achieves constant regret with fixed step-sizes. The cumulative regret of our algorithm provably decreases linearly as the step-size increases. Our findings depart from the prevailing paradigm that vanishing step-sizes are a prerequisite for low regret as championed by all state-of-the-art methods to date. We shift away from this paradigm by defining a novel algorithm that we call Clairvoyant Multiplicative Weights Updates (CMWU). CMWU is Multiplicative Weights Updates (MWU) equipped with a mental model (jointly shared across all agents) about the state of the system in its next period. Each agent records its mixed strategy, i.e., its belief about what it expects to play in the next period, in this shared mental model which is internally updated using MWU without any changes to the real-world behavior up until it equilibrates, thus marking its consistency with the next day's real-world outcome. It is then and only then that agents take action in the real-world, effectively doing so with the "full knowledge" of the state of the system on the next day, i.e., they are clairvoyant. CMWU effectively acts as MWU with one day look-ahead, achieving bounded regret. At a technical level, we establish that self-consistent mental models exist for any choice of step-sizes and provide bounds on the step-size under which their uniqueness and linear-time computation are guaranteed via contraction mapping arguments. Our arguments extend well beyond normal-form games with little effort.