 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Lottery Tickets via SubsetSum: Logarithmic Over-Parameterization is Sufficient
Paper and Code
Jun 14, 2020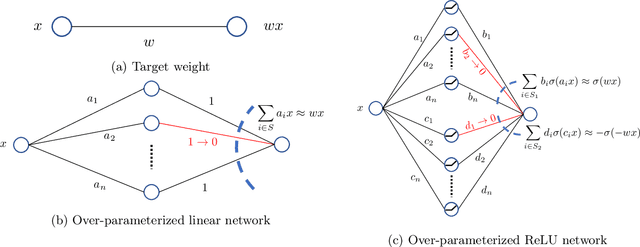

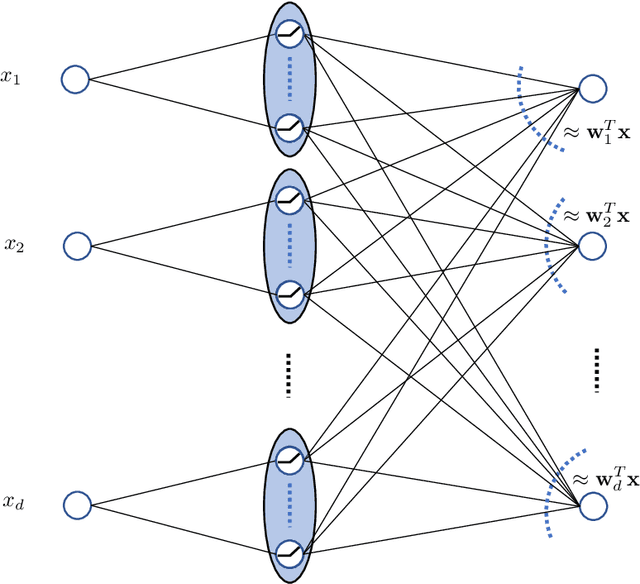
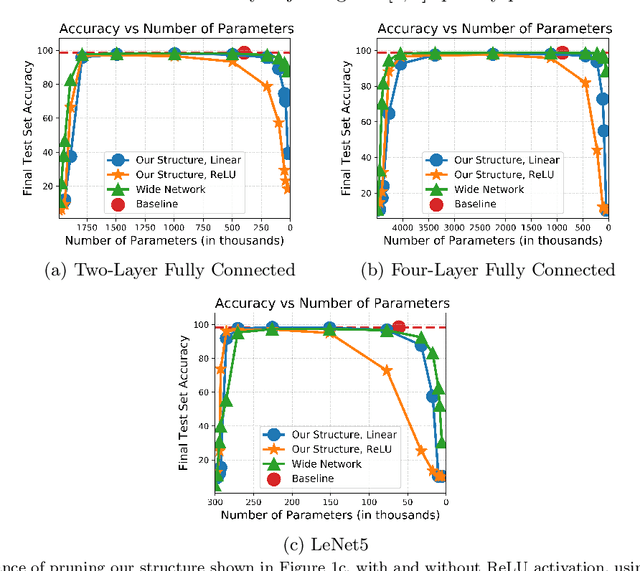
The strong {\it lottery ticket hypothesis} (LTH) postulates that one can approximate any target neural network by only pruning the weights of a sufficiently over-parameterized random network. A recent work by Malach et al.~\cite{MalachEtAl20} establishes the first theoretical analysis for the strong LTH: one can provably approximate a neural network of width $d$ and depth $l$, by pruning a random one that is a factor $O(d^4l^2)$ wider and twice as deep. This polynomial over-parameterization requirement is at odds with recent experimental research that achieves good approximation with networks that are a small factor wider than the target. In this work, we close the gap and offer an exponential improvement to the over-parameterization requirement for the existence of lottery tickets. We show that any target network of width $d$ and depth $l$ can be approximated by pruning a random network that is a factor $O(\log(dl))$ wider and twice as deep. Our analysis heavily relies on connecting pruning random ReLU networks to random instances of the \textsc{SubsetSum} problem. We then show that this logarithmic over-parameterization is essentially optimal for constant depth networks. Finally, we verify several of our theoretical insights with experiments.