 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPIRL: Sample Efficient Off-Policy Inverse Reinforcement Learning via Distribution Matching
Paper and Code


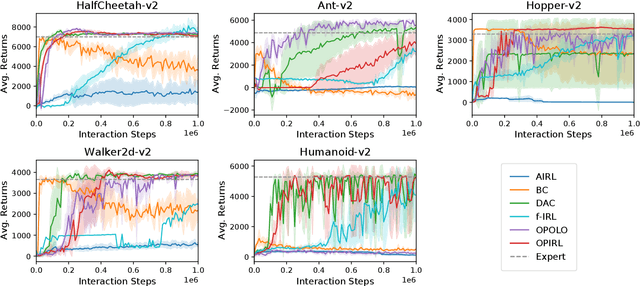
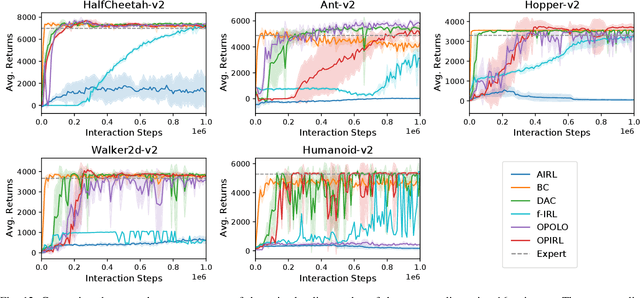
Inverse Reinforcement Learning (IRL) is attractive in scenarios where reward engineering can be tedious. However, prior IRL algorithms use on-policy transitions, which require intensive sampling from the current policy for stable and optimal performance. This limits IRL applications in the real world, where environment interactions can become highly expensive. To tackle this problem, we present Off-Policy Inverse Reinforcement Learning (OPIRL), which (1) adopts off-policy data distribution instead of on-policy and enables significant reduction of the number of interactions with the environment, (2) learns a stationary reward function that is transferable with high generalization capabilities on changing dynamics, and (3) leverages mode-covering behavior for faster convergence. We demonstrate that our method is considerably more sample efficient and generalizes to novel environments through the experiments. Our method achieves better or comparable results on policy performance baselines with significantly fewer interactions. Furthermore, we empirically show that the recovered reward function generalizes to different tasks where prior arts are prone to fail.