 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperation-Level Performance Benchmarking of Graph Neural Networks for Scientific Applications
Paper and Code


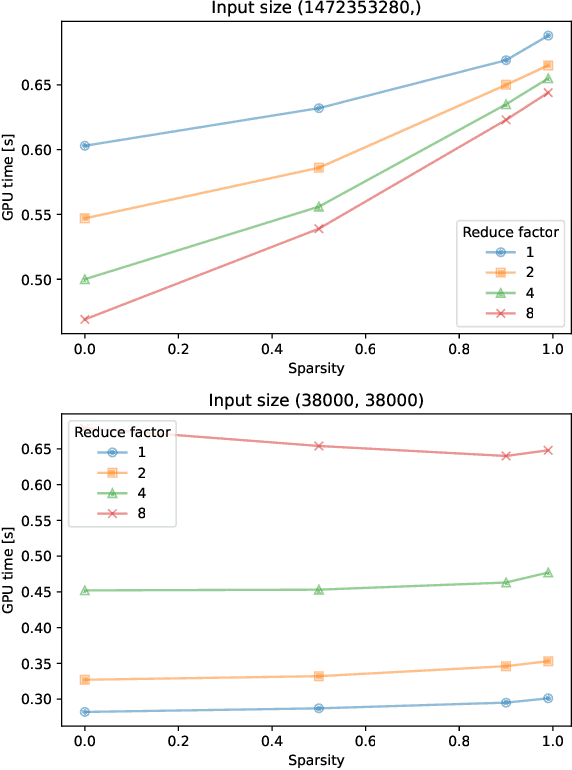
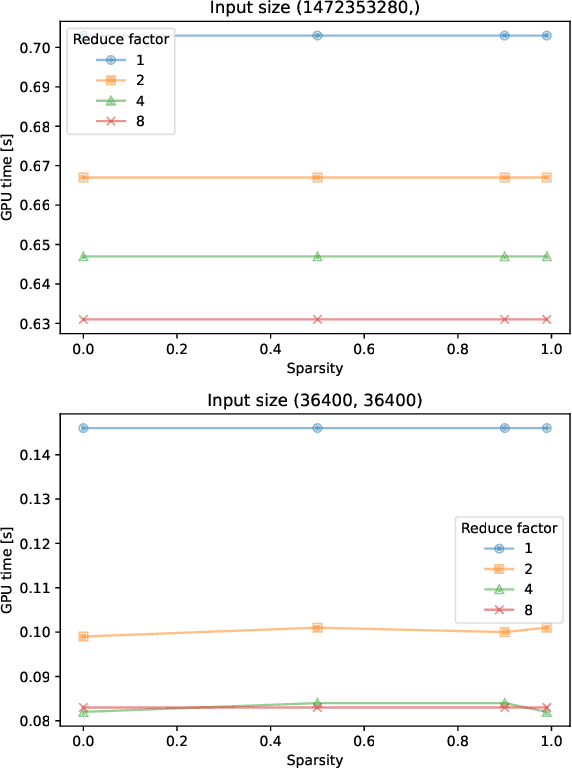
As Graph Neural Networks (GNNs) increase in popularity for scientific machine learning, their training and inference efficiency is becoming increasingly critical. Additionally, the deep learning field as a whole is trending towards wider and deeper networks, and ever increasing data sizes, to the point where hard hardware bottlenecks are often encountered. Emerging specialty hardware platforms provide an exciting solution to this problem. In this paper, we systematically profile and select low-level operations pertinent to GNNs for scientific computing implemented in the Pytorch Geometric software framework. These are then rigorously benchmarked on NVIDIA A100 GPUs for several various combinations of input values, including tensor sparsity. We then analyze these results for each operation. At a high level, we conclude that on NVIDIA systems: (1) confounding bottlenecks such as memory inefficiency often dominate runtime costs moreso than data sparsity alone, (2) native Pytorch operations are often as or more competitive than their Pytorch Geometric equivalents, especially at low to moderate levels of input data sparsity, and (3) many operations central to state-of-the-art GNN architectures have little to no optimization for sparsity. We hope that these results serve as a baseline for those developing these operations on specialized hardware and that our subsequent analysis helps to facilitate future software and hardware based optimizations of these operations and thus scalable GNN performance as a whole.