 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Ended Learning Strategies for Learning Complex Locomotion Skills
Paper and Code
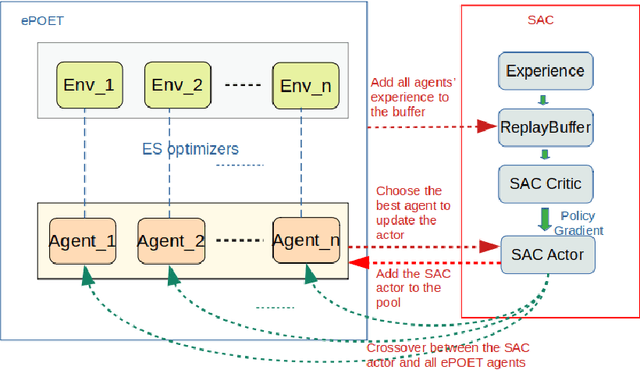

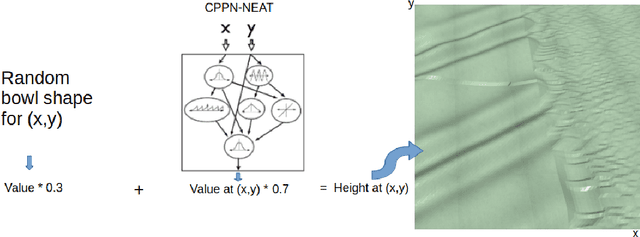

Teaching robots to learn diverse locomotion skills under complex three-dimensional environmental settings via Reinforcement Learning (RL) is still challenging. It has been shown that training agents in simple settings before moving them on to complex settings improves the training process, but so far only in the context of relatively simple locomotion skills. In this work, we adapt the Enhanced Paired Open-Ended Trailblazer (ePOET) approach to train more complex agents to walk efficiently on complex three-dimensional terrains. First, to generate more rugged and diverse three-dimensional training terrains with increasing complexity, we extend the Compositional Pattern Producing Networks - Neuroevolution of Augmenting Topologies (CPPN-NEAT) approach and include randomized shapes. Second, we combine ePOET with Soft Actor-Critic off-policy optimization, yielding ePOET-SAC, to ensure that the agent could learn more diverse skills to solve more challenging tasks. Our experimental results show that the newly generated three-dimensional terrains have sufficient diversity and complexity to guide learning, that ePOET successfully learns complex locomotion skills on these terrains, and that our proposed ePOET-SAC approach slightly improves upon ePOET.