Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Observer-Based Inverse Reinforcement Learning
Paper and Code
Nov 11, 2020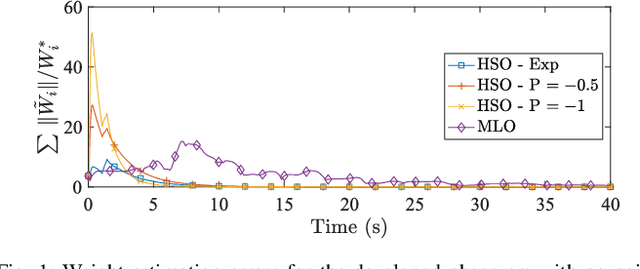
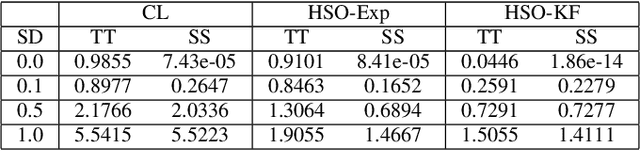
In this paper, a novel approach to the output-feedback inverse reinforcement learning (IRL) problem is developed by casting the IRL problem, for linear systems with quadratic cost functions, as a state estimation problem. Two observer-based techniques for IRL are developed, including a novel observer method that re-uses previous state estimates via history stacks. Theoretical guarantees for convergence and robustness are established under appropriate excitation conditions. Simulations demonstrate the performance of the developed observers and filters under noisy and noise-free measurements.
* 7 pages, 3 figures
View paper on