 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline learning with feedback graphs and switching costs
Paper and Code
Oct 23, 2018
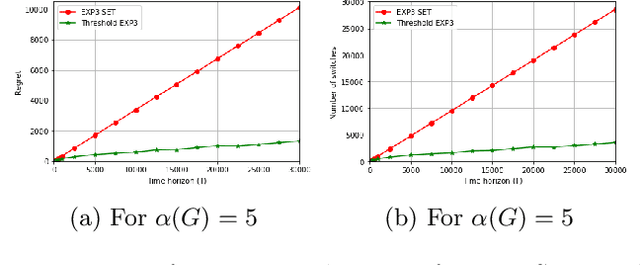
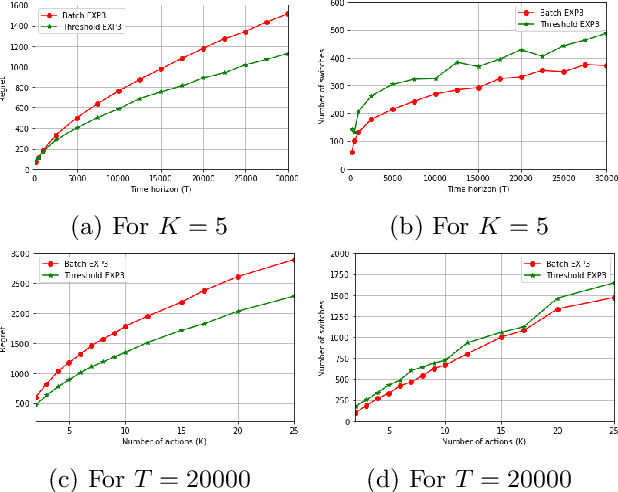
We study online learning when partial feedback information is provided following every action of the learning process, and the learner incurs switching costs for changing his actions. In this setting, the feedback information system can be represented by a graph, and previous work provided the expected regret of the learner in the case of a clique (Expert setup), or disconnected single loops (Multi-Armed Bandits). We provide a lower bound on the expected regret in the partial information (PI) setting, namely for general feedback graphs ---excluding the clique. We show that all algorithms that are optimal without switching costs are necessarily sub-optimal in the presence of switching costs, which motivates the need to design new algorithms in this setup. We propose two novel algorithms: Threshold Based EXP3 and EXP3.SC. For the two special cases of symmetric PI setting and Multi-Armed-Bandits, we show that the expected regret of both algorithms is order optimal in the duration of the learning process with a pre-constant dependent on the feedback system. Additionally, we show that Threshold Based EXP3 is order optimal in the switching cost, whereas EXP3.SC is not. Finally, empirical evaluations show that Threshold Based EXP3 outperforms previous algorithm EXP3 SET in the presence of switching costs, and Batch EXP3 in the special setting of Multi-Armed Bandits with switching costs, where both algorithms are order optimal.