 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning for the Random Feature Model in the Student-Teacher Framework
Paper and Code
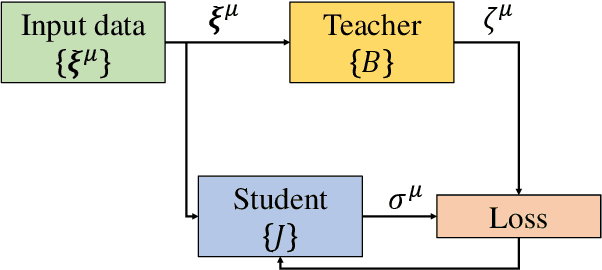
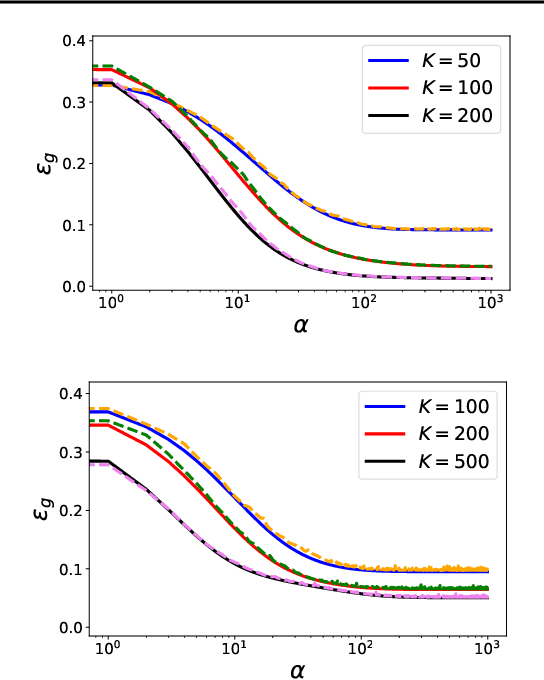
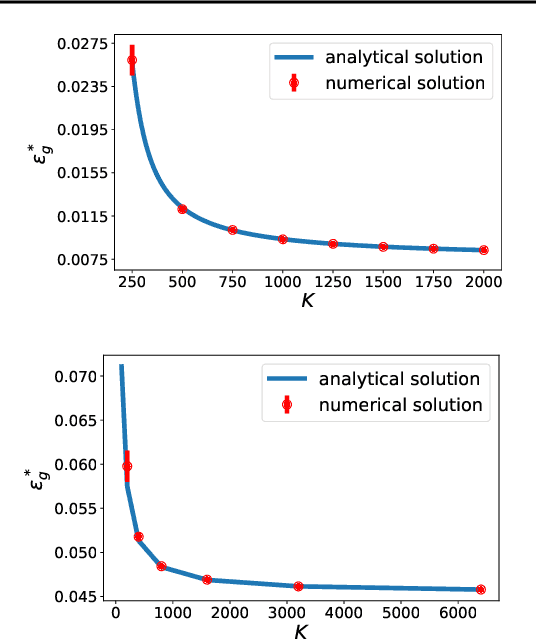
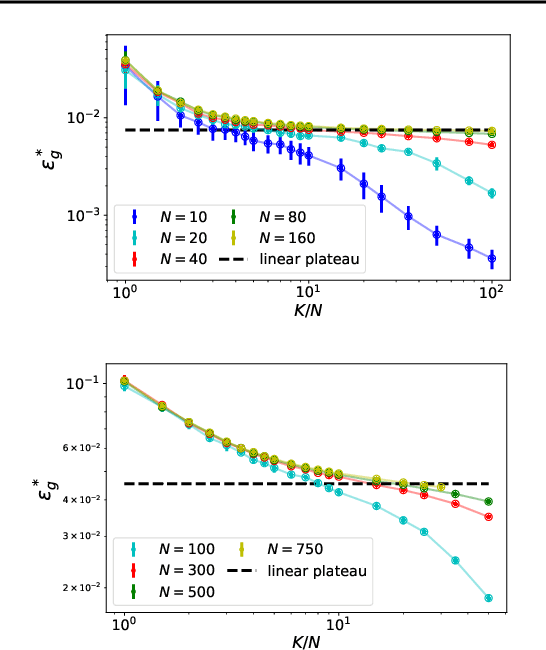
Deep neural networks are widely used prediction algorithms whose performance often improves as the number of weights increases, leading to over-parametrization. We consider a two-layered neural network whose first layer is frozen while the last layer is trainable, known as the random feature model. We study over-parametrization in the context of a student-teacher framework by deriving a set of differential equations for the learning dynamics. For any finite ratio of hidden layer size and input dimension, the student cannot generalize perfectly, and we compute the non-zero asymptotic generalization error. Only when the student's hidden layer size is exponentially larger than the input dimension, an approach to perfect generalization is possible.