 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Learning using Mixture of Variational Autoencoders: a Generalization Learning approach
Paper and Code
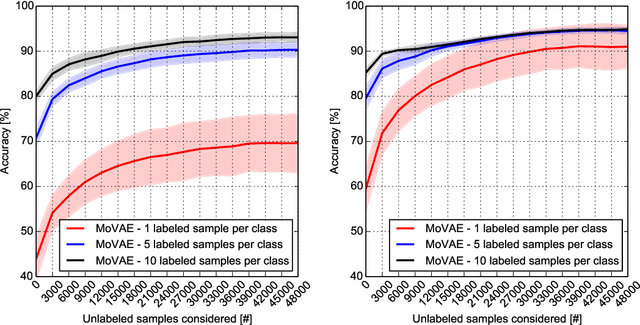



Deep learning, even if it is very successful nowadays, traditionally needs very large amounts of labeled data to perform excellent on the classification task. In an attempt to solve this problem, the one-shot learning paradigm, which makes use of just one labeled sample per class and prior knowledge, becomes increasingly important. In this paper, we propose a new one-shot learning method, dubbed MoVAE (Mixture of Variational AutoEncoders), to perform classification. Complementary to prior studies, MoVAE represents a shift of paradigm in comparison with the usual one-shot learning methods, as it does not use any prior knowledge. Instead, it starts from zero knowledge and one labeled sample per class. Afterward, by using unlabeled data and the generalization learning concept (in a way, more as humans do), it is capable to gradually improve by itself its performance. Even more, if there are no unlabeled data available MoVAE can still perform well in one-shot learning classification. We demonstrate empirically the efficiency of our proposed approach on three datasets, i.e. the handwritten digits (MNIST), fashion products (Fashion-MNIST), and handwritten characters (Omniglot), showing that MoVAE outperforms state-of-the-art one-shot learning algorithms.