 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Nearest-Neighbor Search is All You Need for Minimax Optimal Regression and Classification
Paper and Code
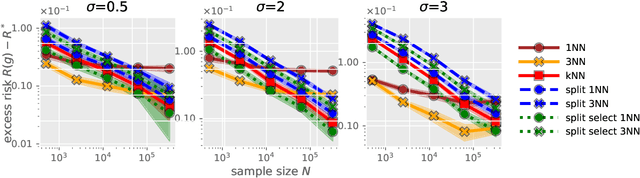
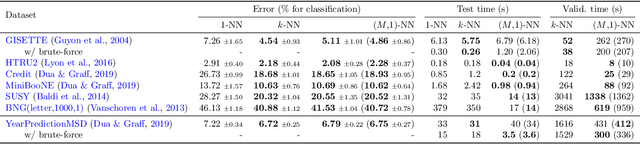
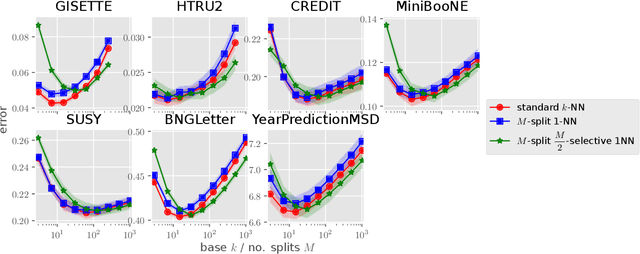

Recently, Qiao, Duan, and Cheng~(2019) proposed a distributed nearest-neighbor classification method, in which a massive dataset is split into smaller groups, each processed with a $k$-nearest-neighbor classifier, and the final class label is predicted by a majority vote among these groupwise class labels. This paper shows that the distributed algorithm with $k=1$ over a sufficiently large number of groups attains a minimax optimal error rate up to a multiplicative logarithmic factor under some regularity conditions, for both regression and classification problems. Roughly speaking, distributed 1-nearest-neighbor rules with $M$ groups has a performance comparable to standard $\Theta(M)$-nearest-neighbor rules. In the analysis, alternative rules with a refined aggregation method are proposed and shown to attain exact minimax optimal rates.