Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-bit feedback is sufficient for upper confidence bound policies
Paper and Code
Dec 04, 2020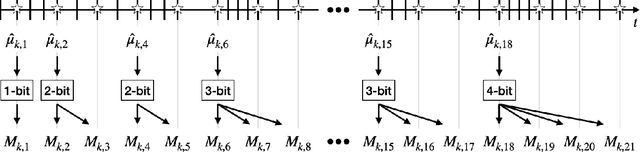

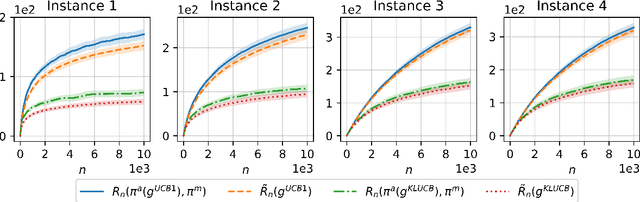
We consider a variant of the traditional multi-armed bandit problem in which each arm is only able to provide one-bit feedback during each pull based on its past history of rewards. Our main result is the following: given an upper confidence bound policy which uses full-reward feedback, there exists a coding scheme for generating one-bit feedback, and a corresponding decoding scheme and arm selection policy, such that the ratio of the regret achieved by our policy and the regret of the full-reward feedback policy asymptotically approaches one.
View paper on