Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Strengths of Cross-Attention in Pretrained Transformers for Machine Translation
Paper and Code


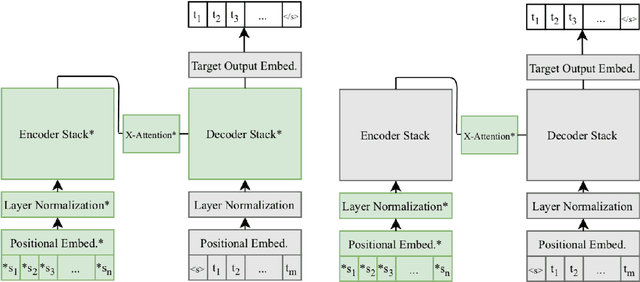

We study the power of cross-attention in the Transformer architecture within the context of machine translation. In transfer learning experiments, where we fine-tune a translation model on a dataset with one new language, we find that, apart from the new language's embeddings, only the cross-attention parameters need to be fine-tuned to obtain competitive BLEU performance. We provide insights into why this is the case and further find that limiting fine-tuning in this manner yields cross-lingually aligned type embeddings. The implications of this finding include a mitigation of catastrophic forgetting in the network and the potential for zero-shot translation.
View paper on