 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sample Complexity of Batch Reinforcement Learning with Policy-Induced Data
Paper and Code
Jun 18, 2021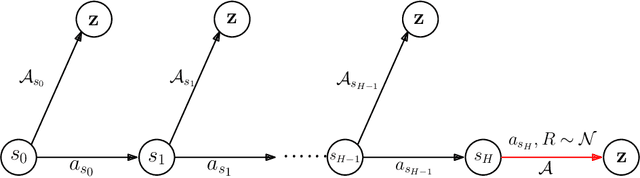

We study the fundamental question of the sample complexity of learning a good policy in finite Markov decision processes (MDPs) when the data available for learning is obtained by following a logging policy that must be chosen without knowledge of the underlying MDP. Our main results show that the sample complexity, the minimum number of transitions necessary and sufficient to obtain a good policy, is an exponential function of the relevant quantities when the planning horizon $H$ is finite. In particular, we prove that the sample complexity of obtaining $\epsilon$-optimal policies is at least $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H+1)})$ for $\gamma$-discounted problems, where $\mathrm{S}$ is the number of states, $\mathrm{A}$ is the number of actions, and $H$ is the effective horizon defined as $H=\lfloor \tfrac{\ln(1/\epsilon)}{\ln(1/\gamma)} \rfloor$; and it is at least $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H)}/\varepsilon^2)$ for finite horizon problems, where $H$ is the planning horizon of the problem. This lower bound is essentially matched by an upper bound. For the average-reward setting we show that there is no algorithm finding $\epsilon$-optimal policies with a finite amount of data.