 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the representation and embedding of knowledge bases beyond binary relations
Paper and Code
Apr 28, 2016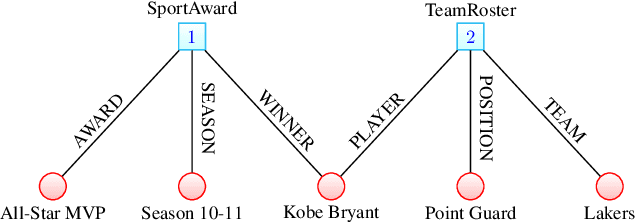

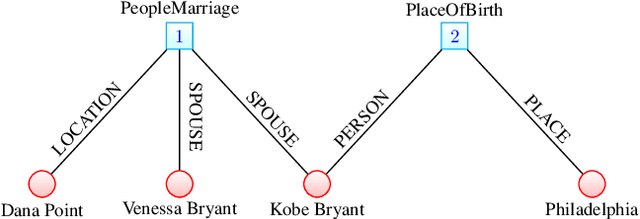
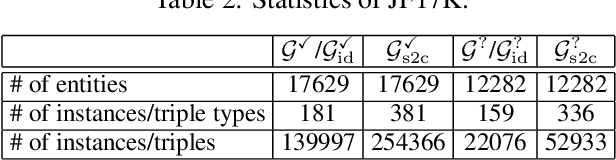
The models developed to date for knowledge base embedding are all based on the assumption that the relations contained in knowledge bases are binary. For the training and testing of these embedding models, multi-fold (or n-ary) relational data are converted to triples (e.g., in FB15K dataset) and interpreted as instances of binary relations. This paper presents a canonical representation of knowledge bases containing multi-fold relations. We show that the existing embedding models on the popular FB15K datasets correspond to a sub-optimal modelling framework, resulting in a loss of structural information. We advocate a novel modelling framework, which models multi-fold relations directly using this canonical representation. Using this framework, the existing TransH model is generalized to a new model, m-TransH. We demonstrate experimentally that m-TransH outperforms TransH by a large margin, thereby establishing a new state of the art.