 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Local Correctness of L^1 Minimization for Dictionary Learning
Paper and Code
Jan 29, 2011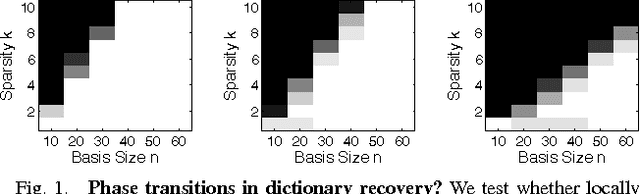
The idea that many important classes of signals can be well-represented by linear combinations of a small set of atoms selected from a given dictionary has had dramatic impact on the theory and practice of signal processing. For practical problems in which an appropriate sparsifying dictionary is not known ahead of time, a very popular and successful heuristic is to search for a dictionary that minimizes an appropriate sparsity surrogate over a given set of sample data. While this idea is appealing, the behavior of these algorithms is largely a mystery; although there is a body of empirical evidence suggesting they do learn very effective representations, there is little theory to guarantee when they will behave correctly, or when the learned dictionary can be expected to generalize. In this paper, we take a step towards such a theory. We show that under mild hypotheses, the dictionary learning problem is locally well-posed: the desired solution is indeed a local minimum of the $\ell^1$ norm. Namely, if $\mb A \in \Re^{m \times n}$ is an incoherent (and possibly overcomplete) dictionary, and the coefficients $\mb X \in \Re^{n \times p}$ follow a random sparse model, then with high probability $(\mb A,\mb X)$ is a local minimum of the $\ell^1$ norm over the manifold of factorizations $(\mb A',\mb X')$ satisfying $\mb A' \mb X' = \mb Y$, provided the number of samples $p = \Omega(n^3 k)$. For overcomplete $\mb A$, this is the first result showing that the dictionary learning problem is locally solvable. Our analysis draws on tools developed for the problem of completing a low-rank matrix from a small subset of its entries, which allow us to overcome a number of technical obstacles; in particular, the absence of the restricted isometry property.