 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the linearity of large non-linear models: when and why the tangent kernel is constant
Paper and Code
Oct 02, 2020

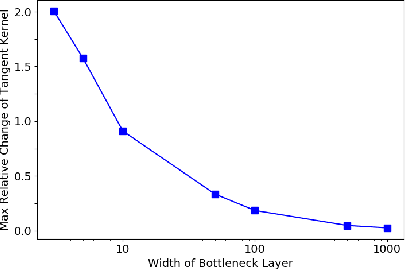
The goal of this work is to shed light on the remarkable phenomenon of transition to linearity of certain neural networks as their width approaches infinity. We show that the transition to linearity of the model and, equivalently, constancy of the (neural) tangent kernel (NTK) result from the scaling properties of the norm of the Hessian matrix of the network as a function of the network width. We present a general framework for understanding the constancy of the tangent kernel via Hessian scaling applicable to the standard classes of neural networks. Our analysis provides a new perspective on the phenomenon of constant tangent kernel, which is different from the widely accepted "lazy training". Furthermore, we show that the transition to linearity is not a general property of wide neural networks and does not hold when the last layer of the network is non-linear. It is also not necessary for successful optimization by gradient descent.