 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Difficulty of Segmenting Words with Attention
Paper and Code
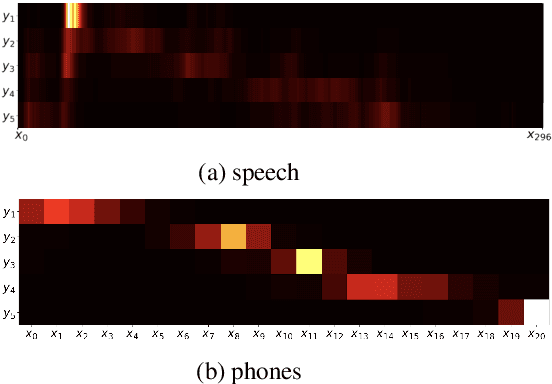

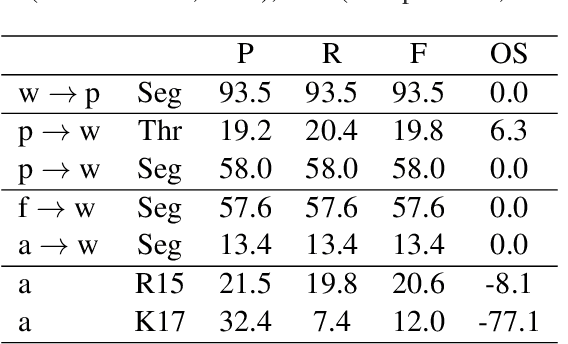
Word segmentation, the problem of finding word boundaries in speech, is of interest for a range of tasks. Previous papers have suggested that for sequence-to-sequence models trained on tasks such as speech translation or speech recognition, attention can be used to locate and segment the words. We show, however, that even on monolingual data this approach is brittle. In our experiments with different input types, data sizes, and segmentation algorithms, only models trained to predict phones from words succeed in the task. Models trained to predict words from either phones or speech (i.e., the opposite direction needed to generalize to new data), yield much worse results, suggesting that attention-based segmentation is only useful in limited scenarios.