 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of the Monte Carlo Exploring Starts Algorithm for Reinforcement Learning
Paper and Code
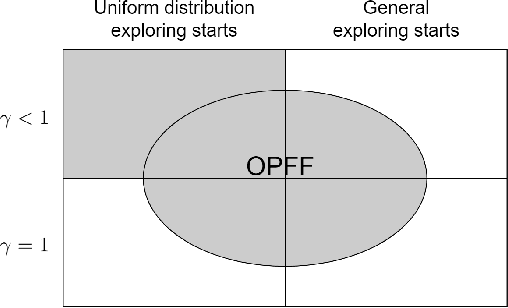
A simple and natural algorithm for reinforcement learning is Monte Carlo Exploring States (MCES), where the Q-function is estimated by averaging the Monte Carlo returns, and the policy is improved by choosing actions that maximize the current estimate of the Q-function. Exploration is performed by "exploring starts", that is, each episode begins with a randomly chosen state and action and then follows the current policy. Establishing convergence for this algorithm has been an open problem for more than 20 years. We make headway with this problem by proving convergence for Optimal Policy Feed-Forward MDPs, which are MDPs whose states are not revisited within any episode for an optimal policy. Such MDPs include all deterministic environments (including Cliff Walking and other gridworld examples) and a large class of stochastic environments (including Blackjack). The convergence results presented here make progress for this long-standing open problem in reinforcement learning.