 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Capacity of Citation Generation by Large Language Models
Paper and Code
Oct 15, 2024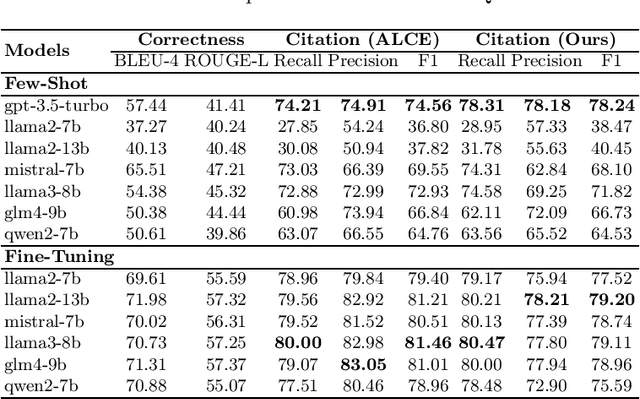
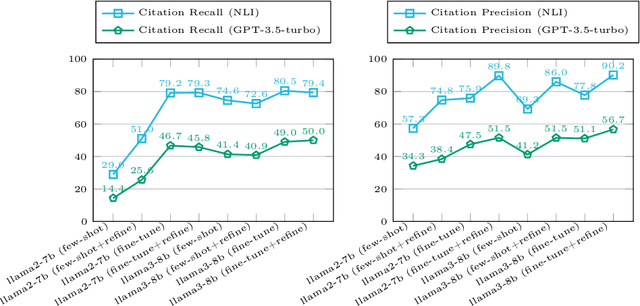
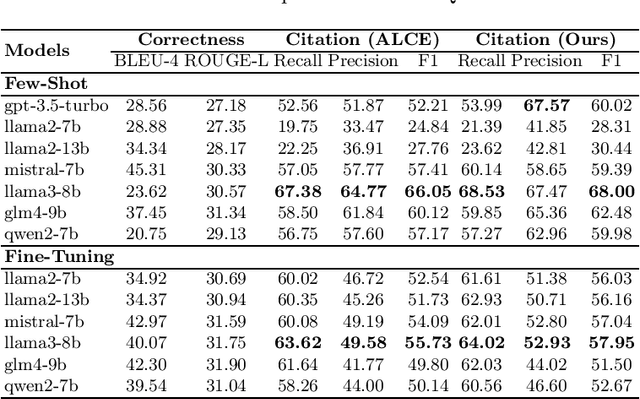
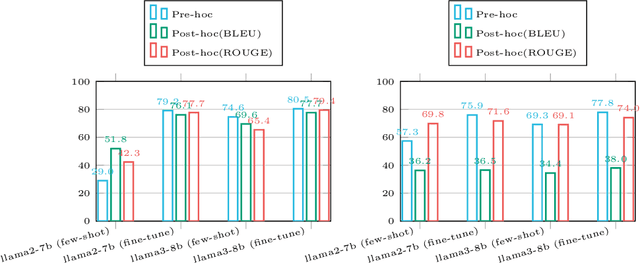
Retrieval-augmented generation (RAG) appears as a promising method to alleviate the "hallucination" problem in large language models (LLMs), since it can incorporate external traceable resources for response generation. The essence of RAG in combating the hallucination issue lies in accurately attributing claims in responses to the corresponding retrieved documents. However, most of existing works focus on improving the quality of generated responses from the LLM, while largely overlooked its ability to attribute sources accurately. In this study, we conduct a systematic analysis about the capabilities of LLMs in generating citations within response generation, and further introduce a novel method to enhance their citation generation abilities. Specifically, we evaluate both the correctness and citation quality for seven widely-used LLMs on two benchmark datasets. Meanwhile, we introduce new citation evaluation metrics to eliminate the over-penalization of unnecessary and excessive citations in existing metrics. Furthermore, we propose a Generate-then-Refine method that completes relevant citations and removes irrelevant ones without altering the response text. The results on WebGLM-QA, ASQA and ELI5 datasets show that our method substantially improves the quality of citations in responses generated by LLMs.