Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the asymptotics of wide networks with polynomial activations
Paper and Code
Jun 11, 2020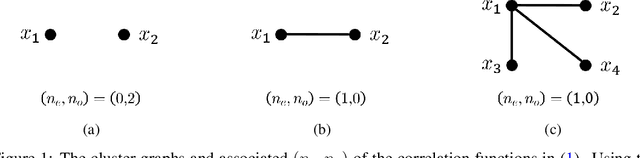
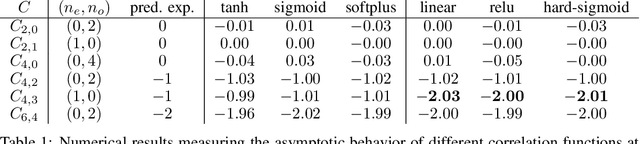
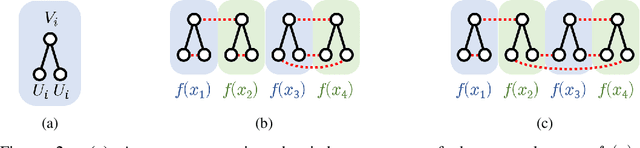

We consider an existing conjecture addressing the asymptotic behavior of neural networks in the large width limit. The results that follow from this conjecture include tight bounds on the behavior of wide networks during stochastic gradient descent, and a derivation of their finite-width dynamics. We prove the conjecture for deep networks with polynomial activation functions, greatly extending the validity of these results. Finally, we point out a difference in the asymptotic behavior of networks with analytic (and non-linear) activation functions and those with piecewise-linear activations such as ReLU.
* 8+12 pages, 6 figures, 2 tables
View paper on