 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Testing and Comparing Fair classifiers under Data Bias
Paper and Code
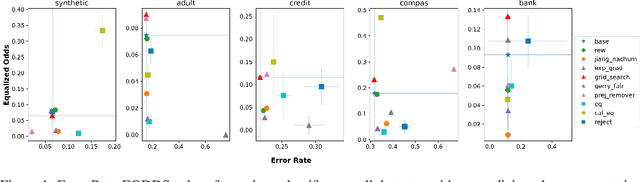
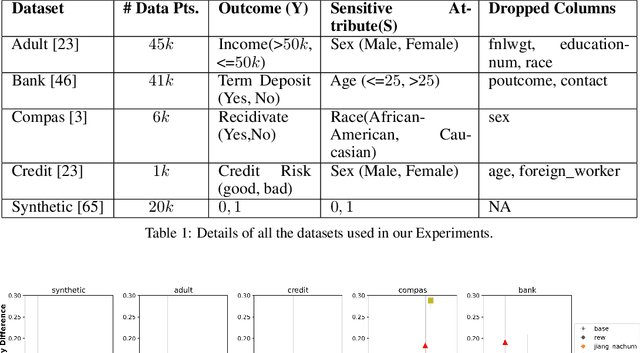
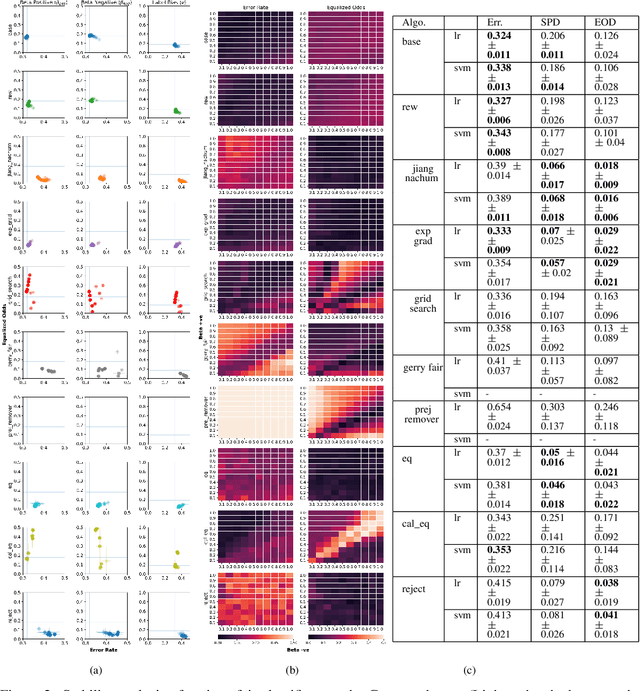
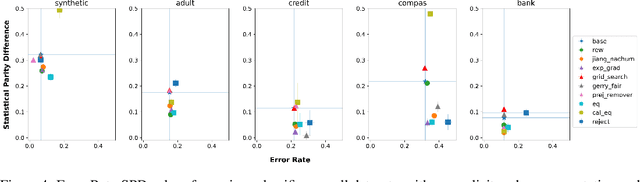
In this paper, we consider a theoretical model for injecting data bias, namely, under-representation and label bias (Blum & Stangl, 2019). We theoretically and empirically study its effect on the accuracy and fairness of fair classifiers. Theoretically, we prove that the Bayes optimal group-aware fair classifier on the original data distribution can be recovered by simply minimizing a carefully chosen reweighed loss on the bias-injected distribution. Through extensive experiments on both synthetic and real-world datasets (e.g., Adult, German Credit, Bank Marketing, COMPAS), we empirically audit pre-, in-, and post-processing fair classifiers from standard fairness toolkits for their fairness and accuracy by injecting varying amounts of under-representation and label bias in their training data (but not the test data). Our main observations are: (1) The fairness and accuracy of many standard fair classifiers degrade severely as the bias injected in their training data increases, (2) A simple logistic regression model trained on the right data can often outperform, in both accuracy and fairness, most fair classifiers trained on biased training data, and (3) A few, simple fairness techniques (e.g., reweighing, exponentiated gradients) seem to offer stable accuracy and fairness guarantees even when their training data is injected with under-representation and label bias. Our experiments also show how to integrate a measure of data bias risk in the existing fairness dashboards for real-world deployments