 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Smart Gaze based Annotation of Histopathology Images for Training of Deep Convolutional Neural Networks
Paper and Code
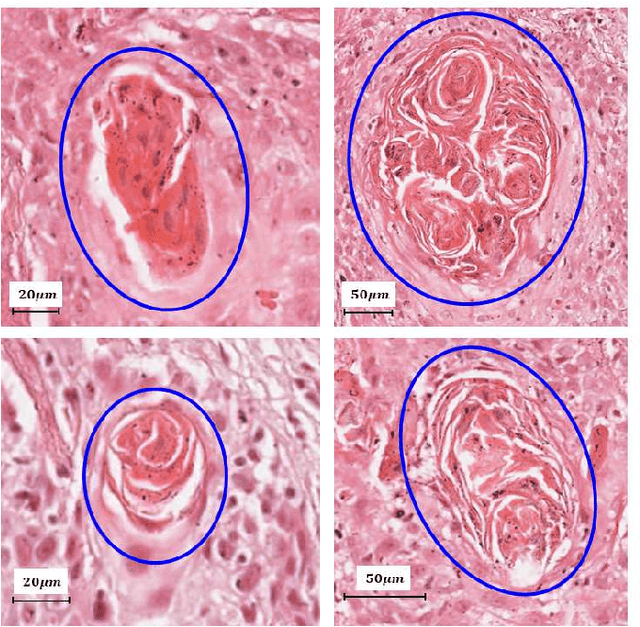
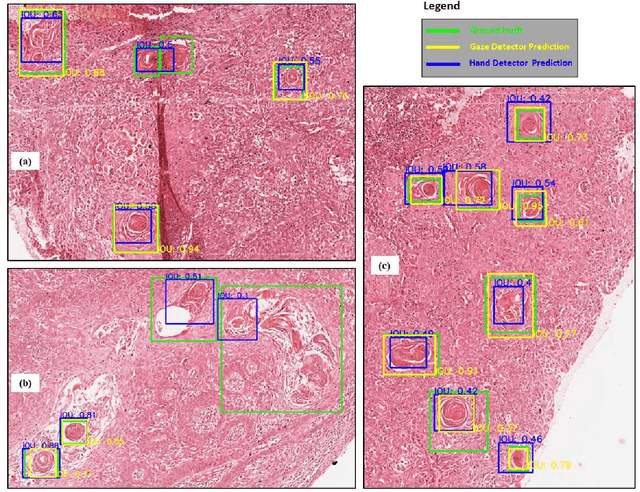
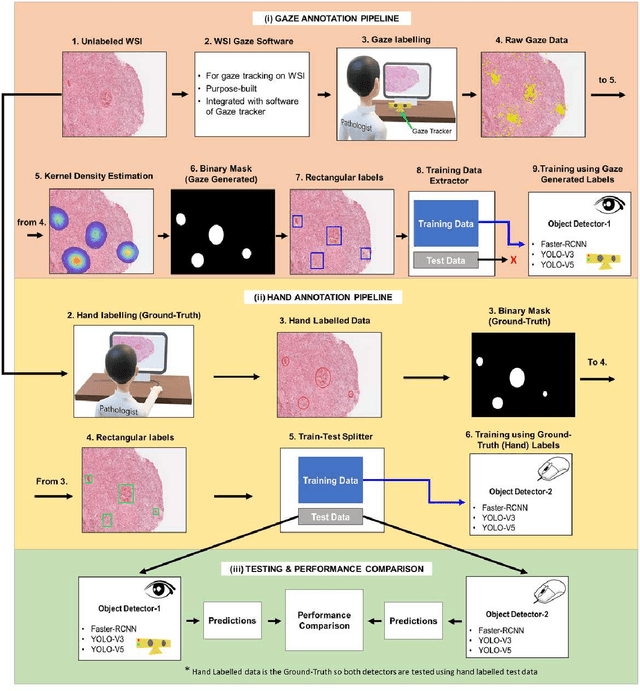
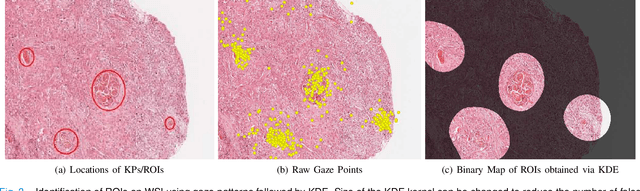
Unavailability of large training datasets is a bottleneck that needs to be overcome to realize the true potential of deep learning in histopathology applications. Although slide digitization via whole slide imaging scanners has increased the speed of data acquisition, labeling of virtual slides requires a substantial time investment from pathologists. Eye gaze annotations have the potential to speed up the slide labeling process. This work explores the viability and timing comparisons of eye gaze labeling compared to conventional manual labeling for training object detectors. Challenges associated with gaze based labeling and methods to refine the coarse data annotations for subsequent object detection are also discussed. Results demonstrate that gaze tracking based labeling can save valuable pathologist time and delivers good performance when employed for training a deep object detector. Using the task of localization of Keratin Pearls in cases of oral squamous cell carcinoma as a test case, we compare the performance gap between deep object detectors trained using hand-labelled and gaze-labelled data. On average, compared to `Bounding-box' based hand-labeling, gaze-labeling required $57.6\%$ less time per label and compared to `Freehand' labeling, gaze-labeling required on average $85\%$ less time per label.