 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Regret-Optimal Learning in Decentralized Multi-player Multi-armed Bandits
Paper and Code
Dec 01, 2016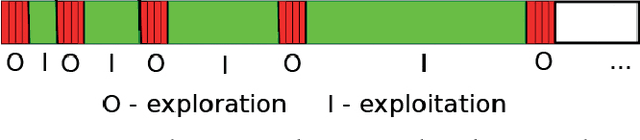
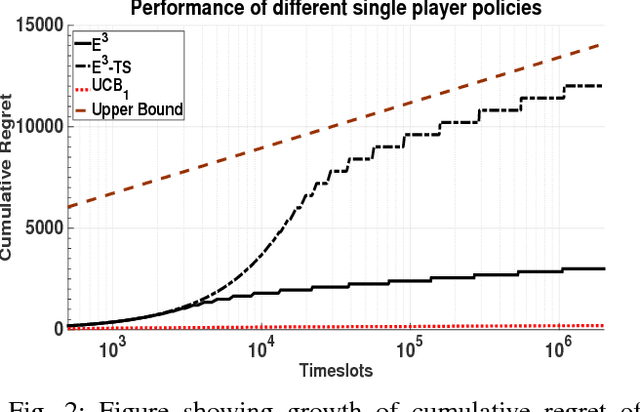
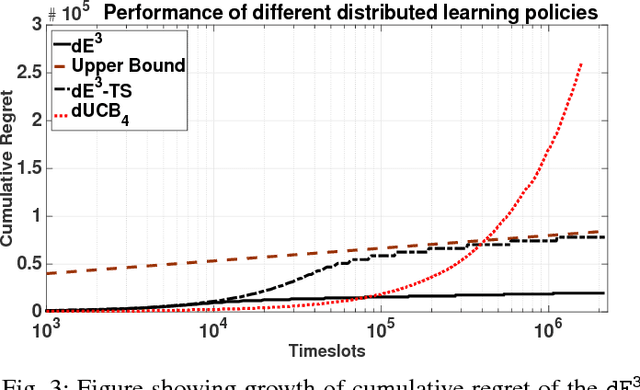
We consider the problem of learning in single-player and multiplayer multiarmed bandit models. Bandit problems are classes of online learning problems that capture exploration versus exploitation tradeoffs. In a multiarmed bandit model, players can pick among many arms, and each play of an arm generates an i.i.d. reward from an unknown distribution. The objective is to design a policy that maximizes the expected reward over a time horizon for a single player setting and the sum of expected rewards for the multiplayer setting. In the multiplayer setting, arms may give different rewards to different players. There is no separate channel for coordination among the players. Any attempt at communication is costly and adds to regret. We propose two decentralizable policies, $\tt E^3$ ($\tt E$-$\tt cubed$) and $\tt E^3$-$\tt TS$, that can be used in both single player and multiplayer settings. These policies are shown to yield expected regret that grows at most as O($\log^{1+\epsilon} T$). It is well known that $\log T$ is the lower bound on the rate of growth of regret even in a centralized case. The proposed algorithms improve on prior work where regret grew at O($\log^2 T$). More fundamentally, these policies address the question of additional cost incurred in decentralized online learning, suggesting that there is at most an $\epsilon$-factor cost in terms of order of regret. This solves a problem of relevance in many domains and had been open for a while.