 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimism in Model-Based Reinforcement Learning
Paper and Code
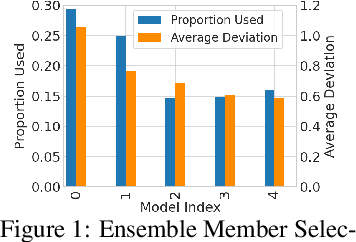
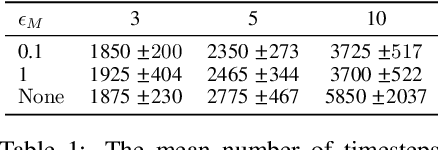


The principle of optimism in the face of uncertainty is prevalent throughout sequential decision making problems such as multi-armed bandits and reinforcement learning (RL), often coming with strong theoretical guarantees. However, it remains a challenge to scale these approaches to the deep RL paradigm, which has achieved a great deal of attention in recent years. In this paper, we introduce a tractable approach to optimism via noise augmented Markov Decision Processes (MDPs), which we show can obtain a competitive regret bound: $\tilde{\mathcal{O}}( |\mathcal{S}|H\sqrt{|\mathcal{S}||\mathcal{A}| T } )$ when augmenting using Gaussian noise, where $T$ is the total number of environment steps. This tractability allows us to apply our approach to the deep RL setting, where we rigorously evaluate the key factors for success of optimistic model-based RL algorithms, bridging the gap between theory and practice.